
티스토리 뷰

Adaptive Prototype Learning and Allocation for Few-Shot Segmentation
CVPR 2021, cited 330
프로토타입 학습은 few-shot segmentation을 위해 광범위하게 사용된다. 일반적으로 global object information을 평균화하여 support feature에서 단일 프로토타입을 얻는다. 그러나 프로토타입 1개로 모든 정보를 representing 하면 모호성을 초래할 수 있다.
본 논문에서는 multiple prototype extraction 및 allocation을 위해 superpixel-guided clustering(SGC)과 guided prototype allocation(GPA)이라는 두 가지 새로운 모듈을 제안한다. 구체적으로, SGC는 매개변수가 없고 훈련이 필요 없는 접근 방식으로, 유사한 feature vectors를 aggregating하여 more representative 프로토타입을 추출하는 반면, GPA는 matched prototypes을 선택하여 more accurate guidance을 제공할 수 있다. SGC와 GPA를 함께 통합하여 경량 모델이며 object scale and shape variation에 적응하는 Adaptive Superpixelguided Network(ASGNet)를 제안한다.
또한, 우리 네트워크는 상당한 개선과 추가 계산 비용 없이 k-shot segmentation로 쉽게 일반화할 수 있다. 특히, COCO에 대한 평가는 ASGNet이 5-shot segmentation.1에서 최첨단 방법을 5% 능가한다는 것을 보여준다

Robust Classification with Convolutional Prototype Learning
cvpr 2018 cited 364
컨볼루션 신경망(CNN)은 이미지 분류에 널리 사용되어 왔다. CNN은 높은 정확도에도 불구하고 일부 adversarial examples에 쉽게 속아 넘어가는 것으로 나타나 CNN이 패턴 분류에 충분히 강건하지 않음을 나타낸다. 본 논문에서는 CNN에 대한 강건성 부족이 완전히 차별적인 모델이며 폐쇄된 세계(즉, 고정된 수의 범주)의 가정을 기반으로 하는 softmax layer에 의해 발생한다고 주장한다.
robustness을 향상시키기 위해 convolutional prototype learning(CPL)이라는 새로운 학습 프레임워크를 제안한다. prototypes을 사용하는 장점은 open world recognition problem을 잘 처리할 수 있어 robustness 을 향상시킬 수 있다는 것이다.
CPL의 프레임워크에서 네트워크를 훈련하기 위해 여러 분류 기준을 설계한다. 또한 특징 표현의 클래스 내 압축성을 개선하기 위한 정규화로 prototype loss(PL)이 제안되며, 이는 다양한 클래스의 Gaussian assumption에 기반한 생성 모델로 볼 수 있다. 여러 데이터 세트에 대한 실험은 CPL이 기존 CNN과 비슷하거나 심지어 더 나은 결과를 달성할 수 있음을 보여주며, robustness 관점에서 CPL은 rejection and incremental category 학습 작업 모두에 큰 이점을 보여준다.
하나는 잘 못 봐서 접음
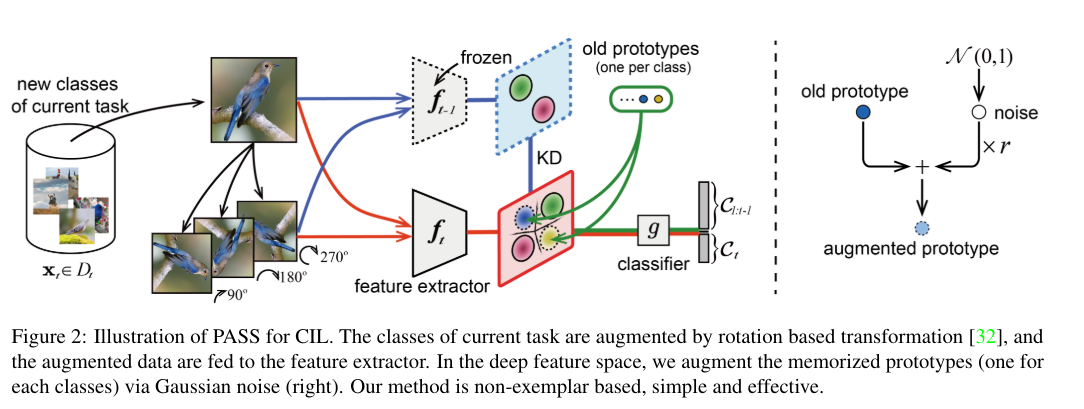
Prototype Augmentation and Self-Supervision for Incremental Learning
cvpr 2021 'cited 296
많은 개별 과제에서 인상적인 성과를 거두었음에도 불구하고, deep neural networks들은 새로운 과제를 점진적으로 학습할 때 catastrophic forgetting에 시달린다.
최근 다양한 incremental learning 방법이 제안되고 있으며, 일부 접근법은 저장된 데이터 또는 복잡한 생성 모델에 의존하여 허용 가능한 성능을 달성했다. 그러나 이전 작업의 데이터를 저장하는 것은 메모리 또는 개인 정보 보호 문제에 의해 제한되며, 생성 모델은 보통 훈련에서 unstable and inefficient.
본 논문에서는 증분 학습에서 치명적인 망각 문제를 해결하기 위해 PASS라는 간단한 nonexemplar based method를 제안한다. (아놔 여기서 drop했어야 됨)
한편으로는 이전 작업의 decision boundary성을 유지하기 위해 이전 클래스별로 one class-representative prototype를 암기하고 프로토타입 증강(ProtoAug)을 deep feature space에 채택할 것을 제안한다. 반면에 우리는 self-supervised learning(SSL)을 사용하여 다른 작업에 대한 더 많은 generalizable 및 transferable 기능을 학습하므로 incremental learning에서 SSL의 효과를 보여준다.
벤치마크 데이터 세트에 대한 실험 결과는 우리의 접근 방식이 non-exemplar based methods를 크게 능가하고 exemplar based 접근 방식과 비교하여 유사한 성능을 달성한다는 것을 보여준다.

(CVPR), 2021 cited 79
Variational Prototype Learning for Deep Face Recognition
Deep face recognition은 center of each class을 나타내는 margin-based softmax loss를 last linear layer에 저장된 prototype에 도입함으로써 현저한 개선을 이루었다. 이러한 방법들에서, training samples들은 clear margin에 의해 positive prototypes에 가깝고 negative prototypes로부터 멀리 떨어져 있도록 강제된다.
그러나, 우리는 prototype learning이 훈련 중 sample-to-sample 비교를 고려하지 않고 sample-to-prototype 비교만 사용하하여 생긴 low loss value를 보건데 sample-to-prototype comparision이 우리에게 perfect feature embedding의 허상만 주고 사실은 SGD의 추가 탐색을 방해한다고 주장한다.
이를 위해 latent space의 한 점 대신 모든 계층을 분포로 나타내는 Variational Prototype Learning(VPL)을 제안한다.
slow feature drift 현상을 식별하여 프로토타입에 memorized features를 직접 주입하여 variational prototype sampling을 근사화한다. 제안된 VPL은 classification framework 내에서 샘플 간 비교를 시뮬레이션하여 SGD solver가 더 탐색적(exploratory)이 되도록 장려하는 동시에 성능을 향상시킬 수 있다. 또한 VPL은 개념적으로 간단하고 구현하기 쉬우며 계산 효율적이며 메모리를 절약한다. 인기 있는 벤치마크에 대한 광범위한 실험 결과를 제시하여 최첨단 경쟁사에 비해 제안된 VPL 방법의 우수성을 입증한다.

Prototype vector machine for large scale semi-supervised learning
ICML '09 cited 141

실제적인 데이터 마이닝은 supervised learning 시나리오에 정확히 들어가는 경우는 거의 없다. 오히려 늘어나는 unlabeled data의 양은 large-scale semi-supervised learning(SSL)에 큰 도전이 되고 있다. 우리는 graph-based SSL의 computational intensiveness이 manifold or graph regularization에서 크게 발생하고, 이는 결국 다루기 어려운 대형 모델로 이어진다는 점에 주목한다.
이를 완화하기 위해 대규모 SSL을 위한 highly scalable한 graph-based algorithm인 prototype vector machine(PVM)을 제안했다. 우리의 key innovation은 both the graphbased regularizer 및 model representation에 대한 효율적인 근사치를 위해 “prototypes vectors”를 사용하는 것이다.
프로토타입의 선택은 다음 두 가지 중요한 기준을 기반으로 한다:
kernel 행렬의 efficient low-rank approximation을 수행할 뿐만 아니라 complete 모델과 비교하여 minimum information loss을 겪는 모델까지 span 한다(포함한다?). 우리는 number of ML benchmark data sets에서 PVM의 고무적인 성능과 appealing한 스케일링 특성을 보여준다.
'AI' 카테고리의 다른 글
| VLM-PL: Advanced Pseudo Labeling Approach for Class Incremental Object Detection via Vision-Language Model (0) | 2024.06.25 |
|---|---|
| Gaussian Mixture Model 의 Clustering (0) | 2024.06.24 |
| [Mnemonics Training]CVPR'2020 (2) | 2024.06.02 |
| [LUCIR] CVPR'2019 (1) | 2024.06.01 |
| Herding Dynamical Weights to Learn (0) | 2024.06.01 |
- Total
- Today
- Yesterday
- Arbitrary image stylization
- 첫논문
- 딥페이크탐지
- batch란
- Deformable Part Model
- /var/log/tallylog
- /var/log/faillog
- 도메인 어댑테이션
- StyleCLIP
- tensorflow convert
- Source-free unsupervised domain adaptation
- Deformable Convolutional Networks
- textual guidance
- alternatives.log
- Chatgpt4
- ctfloader
- TransferLearning
- 1-stage detection
- /var/log/alternatives.log
- DetectoRS
- 전이학습
- torchmodel
- /var/log/fontconfig.log
- tf2to1
- max-margin_loss
- tf version porting
- Group Acitivty Recognition
- neural network applications
- yolov3 #tensorflow_convert
- 샴네트워크
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |