
티스토리 뷰
2024.03.21 - [AI] - Deep Visual Domain Adaptation: A Survey 읽기
오늘은 one-step과 multi-step을 볼테니 논문에 참조된 테이블을 먼저 보자.
| One-step DA 접근 | 요약 | Subsettings (하위집합) |
| Discrepancy(불일치)기반 | label/unlabel 타겟 데이터를 통해 deep network를 파인튜닝한다. 그리하여 domain shift를 줄인다. | class (분류) 기준 |
| statistic(통계) 기준 | ||
| architecture (구조)기준 | ||
| geometric (기하)기준 | ||
| Adversarial(적대) 기반 | adversarial 목적을 가지고 domain discriminator(판별기)를 통해 domain confusion을 촉진한다. | generative(생성) models |
| non-generative(비생성) models | ||
| Reconstruction(재구성) 기반 | data reconstruction을 보조 작업으로 활용해 특징 invariance를 강화한다. | 인코더-디코더 reconstruction |
| 적대적 reconstruction |
| Multi-step DA접근 | 요약 |
| Hand-crafted | 사용자는 경험적으로 중간 도메인을 결정한다. |
| Instance-based | auxiliary 데이터셋 일부분을 모아서 중간 도메인을 구성한다. |
| Representation(표현)-기반 | 네트워크 하나를 얼려서 가중치의 중간 표현(representation)을 새로운 네트워크의 입력으로 삼는다. |

- Target domain type
- Supervised DA with labeled data
- Semi-supervised DA with labeled and unlabeled data
- non-supervised DA with unlabeled data.
- 두 번째 설정은 1.과 3.의 방법을 결합하여 수행가능하기에 본 논문에서는 1,3 설정에만 초점을 맞춘다. 각 DA 설정에 대해 서로 다른 접근 방식이 주로 사용되는 경우는 표 III와 같다. 보이는 바와 같이, Supervised DA는 한계가 있기 때문에 감독되지 않은 장면에 더 많은 작업이 집중된다. 대상 도메인에서 레이블이 지정된 데이터만 사용할 수 있는 경우, 모델의 매개 변수를 훈련하기 위해 src 및 tgt 레이블이 지정된 데이터를 사용하면 일반적으로 src distribution 에 과적합이 발생한다. 또한 discrepancy-기반 접근 방식은 수년 동안 연구되어 많은 연구 작업에서 더 많은 방법을 생산한 반면, adversarial 기반 및 reconstruction 기반 접근 방식은 비교적 새로운 연구 주제이지만 최근에 더 많은 관심을 받고 있다.

A. Homogeneous Domain Adaptation
1) Discrepancy(불일치)기반 Adaptation :
- Yosinski et al. 이 Deep networks가 학습한 transferable 한 특징들이 fragile co-adaptation 과 represntation specifity 때문에 한계가 있다고 했다.
- 그리고 fine-tuning이 generalization 성능을 향상시킬 수 있음을 입증했다.
- fine-tuning은 소스 데이터로 기본네트워크를 훈련시킨 다음 처음 n개 layer를 directly 재사용하여 target network를 수행한다. target network의 나머지 레이어는 무작위로 초기화 되고 discriepancy기반한 loss로 학습된다.
- 훈련 중에 타겟 네트워크의 처음 n개의 레이어는 타겟 데이터셋의 크기와 소스 데이터 세트와의 similarity 에 따라 미세 조정되거나 동결될 수 있다.
- 주된 시나리오를 탐색하기 위한 몇가지 일반적인 common rule이 표 4 에 있다.
표 4Target Dataset 크기 작음 중간 큼 Source와 Target 사이 거리 좁음 Freeze 얼려보거나 튜닝 튜닝 중간 얼려보거나 튜닝 튜닝 튜닝 넓음 얼려보거나 튜닝 튜닝 튜닝

- Class Criterion
- Basic training loss in deep DA
- src data 사전학습 후 타겟모델의 나머지 레이어(아마도 -5)는 클래스 라벨 정보를 네트워크를 학습시키기 위한 가이드로 삼는다. 그래서 타겟데이터의 적은 샘플(라벨有)이 이용가능할 것이라 가정한다. 이상적으로는 지도 DA에서 클래스 라벨정보가 직접적으로 주어진다.
- 대부분의 작업은 보통 그들의 loss(L)로서 SoftMax를 낀 ground truth 의 negative-loglikelihood를 이용한다.

- 이를 확장하기 위해 Hinton들은 softmax함수를 soft label loss로 수정했다.

- T 는 표준 Softmax에서 1로 정해진 temperature 이지만 하지만 클래스에 대한 보다 부드러운(softer?) 확률분포를 만들려면 보다 높은 값을 필요로 한다. 이 높은 값을 이용하면, 더 작은 확률 비율에서도 유의미한 정보를 얻을 수 있을 것이다.
더보기숫자인식을 예로 들어보자. 예를 들어 숫자 숫자 2(휘갈겼다고 하자)를 3과 비슷할 확률을 $10^-6$으로 표현하고 7과 비슷할 확률은 $10^-9$로 표현하는 글씨체(경우)도 있을 것이다. 달리 말해 이 버전은 2가 7보다는 3과 유사해보인다는 것이다. 즉 T를 높이는 것이 낮은 확률 $10^-6$과 $10^-9$ 사이에서도 information 을 얻게 하는 것이다.
- Hinton에게 영감을 받은 Simultaneous deep transfer across domains and tasks 는 Domain Confusion Loss(IV-A2 섹션에서 설명할 Adverseraial 기반 접근법에 속함)과 Soft label loss를 동시에 최소화하여 네트워크를 fine-tuning했다.
- 하드 라벨이 아닌 소프트 라벨을 사용하면 도메인 간 클래스 간의 관계를 보존할 수 있다.
- Gebru는 Simultaneous deep transfer across domains and tasks 을 기반으로 기존 적응 알고리즘을 수정하고 fine-grained class level $L_{csoft}$ 와 Attribute level $ L_{asoft} $ 영역에서 soft label loss을 활용했다

- softmax loss 이외에도 supervised DA에서 target model를 fine-tuning하기 위한 train loss로 사용하는 다른 방법들이 있다. Metric learning을 deep networks에 embedding하는 것은 동일한 레이블을 가진 다른 도메인의 샘플들의 거리를 다른 레이블을 가진 샘플들이 멀리 있는 동안 더 가깝게 만들 수 있는 또 다른 방법이다.
- 이 아이디어를 기반으로 [79] Unified deep supervised domain adaptation and generalization (17') 에서는 semantic alignment loss와 그에 따른 separation loss를 만들었다. (construct). Deep transfer metric learning 은 제안한 논문[53]에서 marginal(변두리의) Fisher analysis criterion 과 MMD criterion (통계 criterion 에서 설명함)을 적용해 distribution difference를 최소화 했다:

- α , , $\gamma $는 정규화 파라미터이고 $W^{(m)}$ 및 $b^{(m)}$는 네트워크 $m^{th}$번째 계층의 weights 와 biases다.
- ${D_{ts}}^{(M)}(X^s,X^t)$ : Src와 Tgt Domain 표현 간의 MMD 이다.
- $S_c$와 $S_b$는 클래스간 compactness(조밀함)과 interclas separability(구분성)을 의미한다.
- 그러나!
- Target Domain에 직접적인 클래스 라벨 정보가 없다면 어떻게 할까?
- 사람은 high-level 설명만 들어도 한 번도 본 적 없는 클래스를 식별할 수 있다. 예를 들어 "키가 크고 긴 목을 지닌 갈색의 동물이에요" 라고 하면 기린을 인식할 수 있다.
- 인간의 능력을 모방하기 위해 [64] Learning to detect unseen object classes by between-class attribute transfer('09) 는 클래스당 high-level semantic attribute는 도입하였다.
- 가정해보자. $a^c=a_1^c$, $...$,$a_m^c$) 가 class c 의 attribute 표현이다. 모든 클래스에서 고정길이의 binary value를 m개의 속성으로 갖고 있는 것이다.
- Classifier는 각 속성 $a_m$마다 $p(a_m|x)$ 에 대한 예측값을 제공한다.
- test 단계에서, 각 target class $y$는 각 클래스의 속성 벡터인 $a^y$ 를 deterministic 한 방법을 통해 얻는다.
- 예를 들어, $p(a|y)=[a=a^y]$. 같은 방식으로 말이다.
- 베이지안 룰을 적용하면, $p(y|a)$= $\frac{p(y)}{p(a^y)}$[a=$a^y$] , 인데, test class의 posterior(특정 클래스 y로 추측했을 때 입력이 x일 확률) 은 다음과 같이 계산할 수 있다.

이미지에서 속성 a를, 속성 a를 통해서 y를 추측할 확률을 곱해야 한다. 속성은m개니 곱셈 연산은 속성 갯수 만큼 이뤄지는 것이다. 속성의 갯수만큼 x로 부터 해당 속성이 나오는 것을 곱한다. 그리고 class y에 대한 속성이 나올 확률로 class y의 확률을 나눈다.
- Gebru가 [29]Fine-grained recognition in the wild: A multi-task domain adaptation approach(17')가 이것에 영감을 받아 속성을 확용하여 fine-grained Recognition(세밀한 인식)의 DA에서 성능을 향상 시켰다. Target model을 fine-tune하기 위해 Attribute와 class 수준을 동시에 수행하는 복수의 independent softmax loss 들이 있다.
- Independent classifiers가 attribute 와 class level에서 얻은 labels와 충돌한다면? 이를 방지하기 위해 attribute consistency loss란 것
도을 만들었다.
- 때때로 비지도 DA에서 네트워크를 fine-tuning 할 때, psudo label이라 불리는 target data의 라벨은 maxium posterior probability 에 기반하여 미리(사전에) 획득도 가능하다.
- Yan 는 [130] Mind the class weight bias: Weighted maximum mean discrepancy for unsupervised domain adaptation(17')에서 source data를 사용해 target model을 초기화 한 다음 target 모델의 Output으로 class posterior 확률 $p(y_j^t=c|x_j^t)$를 정의했다.
- $p(y_j^t=c|x_j^t)$ 를 이용해 그들은 pseudo-label $\widehat{y}_j^t$을 $x_j^t)로 할당하는데 아래 수식을 사용했다.
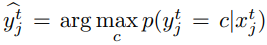
- 어떤 논문[98]에서는 두개의 다른 네트워크가 unlabeld 샘플에 psudo 라벨을 할당하고, 또다른 네트워크는 target discriminative reprentation을 얻기 위한 샘플들로 학습했다.
- [139]Deep transfer network(DTN)은 SVM이나 MLP같은 기본적인 분류기를 사용했었다. 목적은 target sample에 대한 psudo label을 얻어 target sample에 대한 조건분포를 추측했다. MMD criterion(기준)으로 그 조건부 분포와 그 주변(marginal) 분포를 둘이서 match 시키는 것이다.
- 이 다음은 제대로 이해했는지 모르겠음
오늘은 one-step과 multi-step을 볼테니 논문에 참조된 테이블을 먼저 보자.
-
- Classifier adaptation을 Residual Learning frame work (Resnet 말하는 것 같다) 에 Casting 할 때, 어떤 논문 [75]는 psudo label을 사용해 조건부 엔트로피 $E$($D^t$ ,$f^t$) 를 구축했다. 이를 통해 target Classifier 인 $f^t$
- 졸려서 오늘을 여기까지.
'AI' 카테고리의 다른 글
| 0325 papers + CI-UDA (2) | 2024.03.25 |
|---|---|
| Deep Visual Domain Adaptation: A Survey 3 (0) | 2024.03.25 |
| Deep Visual Domain Adaptation: A Survey 읽기 (0) | 2024.03.21 |
| DiffStyler: Controllable Dual Diffusion forText-Driven Image Stylization (0) | 2024.03.14 |
| 인공지능학술대회 논문을 읽어보자 (0) | 2024.03.11 |
- Total
- Today
- Yesterday
- TransferLearning
- 1-stage detection
- textual guidance
- /var/log/fontconfig.log
- Arbitrary image stylization
- /var/log/tallylog
- Deformable Convolutional Networks
- Group Acitivty Recognition
- max-margin_loss
- tensorflow convert
- tf2to1
- 샴네트워크
- tf version porting
- alternatives.log
- batch란
- 딥페이크탐지
- ctfloader
- yolov3 #tensorflow_convert
- /var/log/faillog
- /var/log/alternatives.log
- 전이학습
- Deformable Part Model
- 도메인 어댑테이션
- 첫논문
- Chatgpt4
- torchmodel
- DetectoRS
- Source-free unsupervised domain adaptation
- StyleCLIP
- neural network applications
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |