
티스토리 뷰
-5장 이상은 죽어도 안보겠다는 생각으로 게시물 작성하기 (일부 지난 과제 ppt 활용)

일단 GAN과 text to Image 를 좀 알아봤음.
-https://www.slideshare.net/NaverEngineering/1-gangenerative-adversarial-network
-https://arxiv.org/pdf/1406.2661.pdf
-https://www.youtube.com/watch?v=odpjk7_tGY0 굳이 먹여주는데 입 안벌릴 필요 없음(스압)
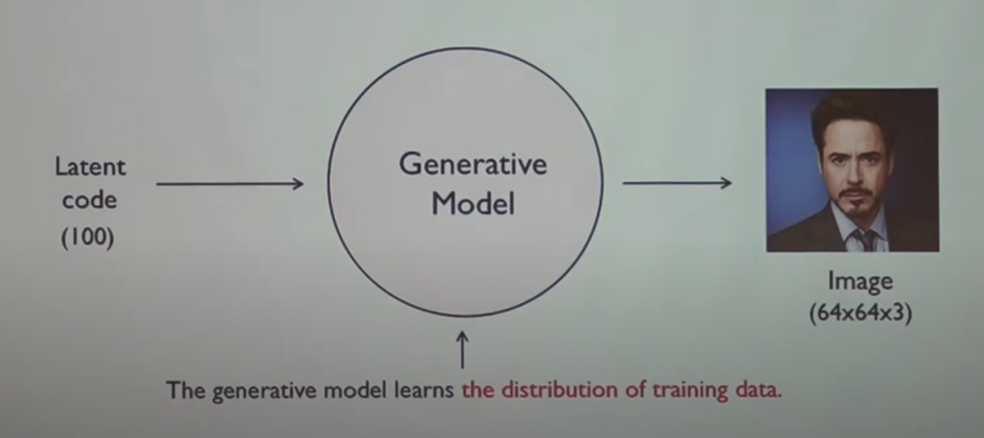


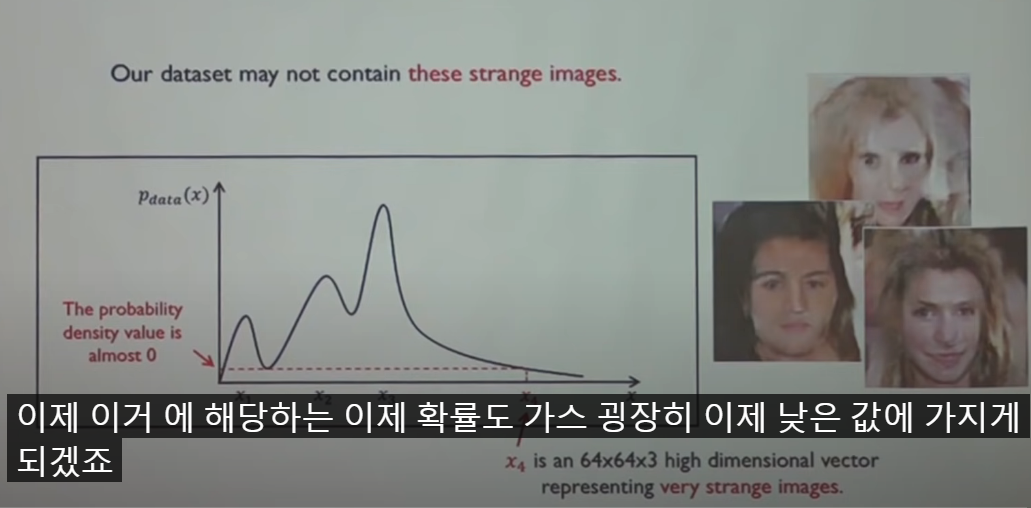
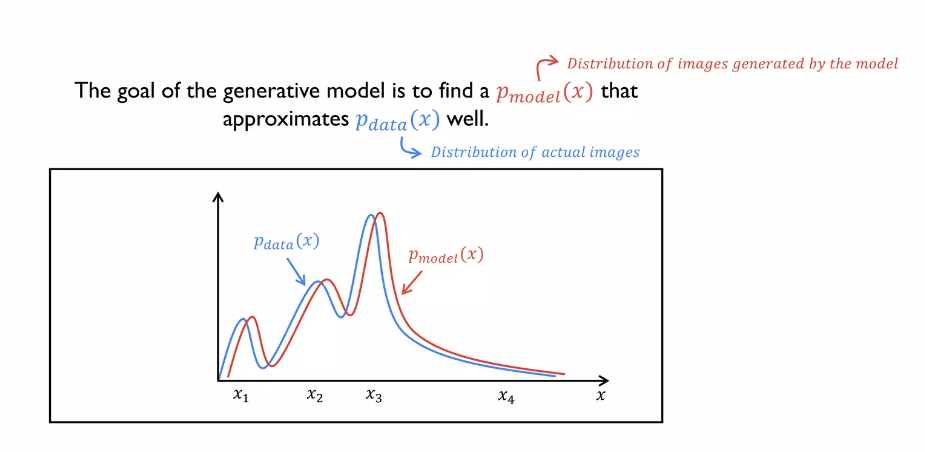

G는 D를 속여서 최소값을 만들게 하는 것인데, 1항에서는 쪽쓸 수 없으니 2항에서 최대한 D를 벗겨먹어야 한다. 2항 값을 log 0을 만들면 할 수 있다.

https://youtu.be/odpjk7_tGY0?t=821
예제도 있다고 함 : https://github.com/yunjey/pytorch-tutorial



시간나면 볼 것
- DCgan - pooling을 안씀 대신 strid =2 의 conv를 썼음. adam optimizer를 씀. (값이 현업에서 자주 쓰인다고 함)

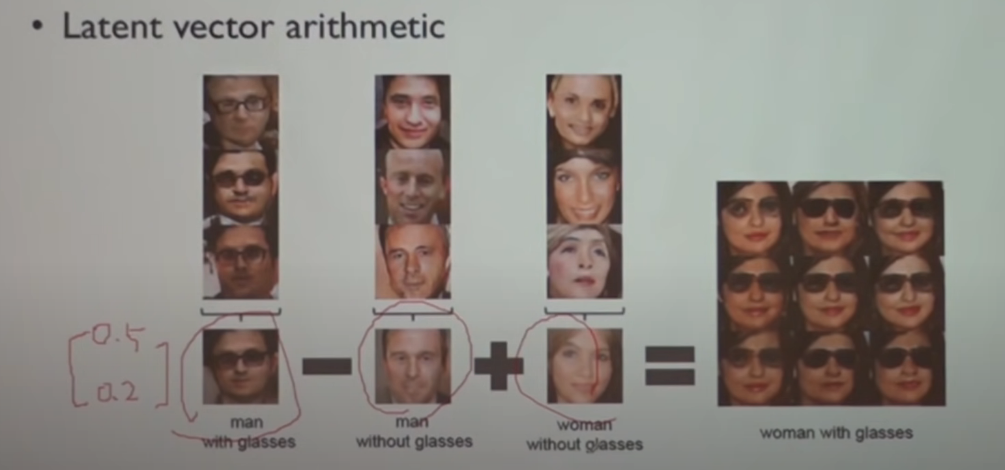

- LSGAN(least Squares GAN)
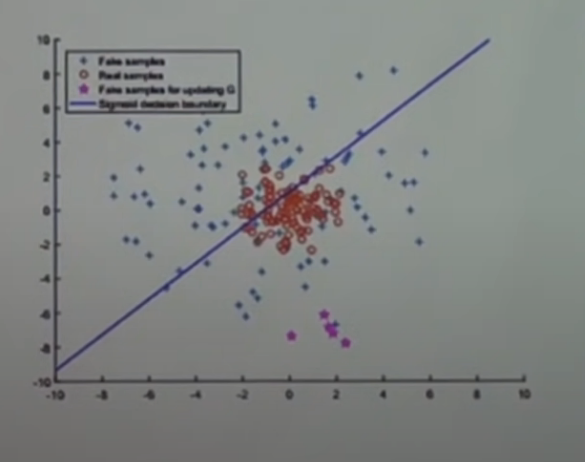

Sgan


//질문에서 one/hot 으로 분류하는 지점에 =대해서 2라고하면 trended 하게 그냥 번듯한 2 하나만 (다른 스타일없이) generate 되는 거 아니냐고 40분쯤에 이야기했는데 그런거 없이 잘 generate 된다고 함
-Auxiliary Classifier ACGAN
inception score
CycleGAN (유명한 Cgan!!) -main idea is closely perfectly same as DiscoGAN

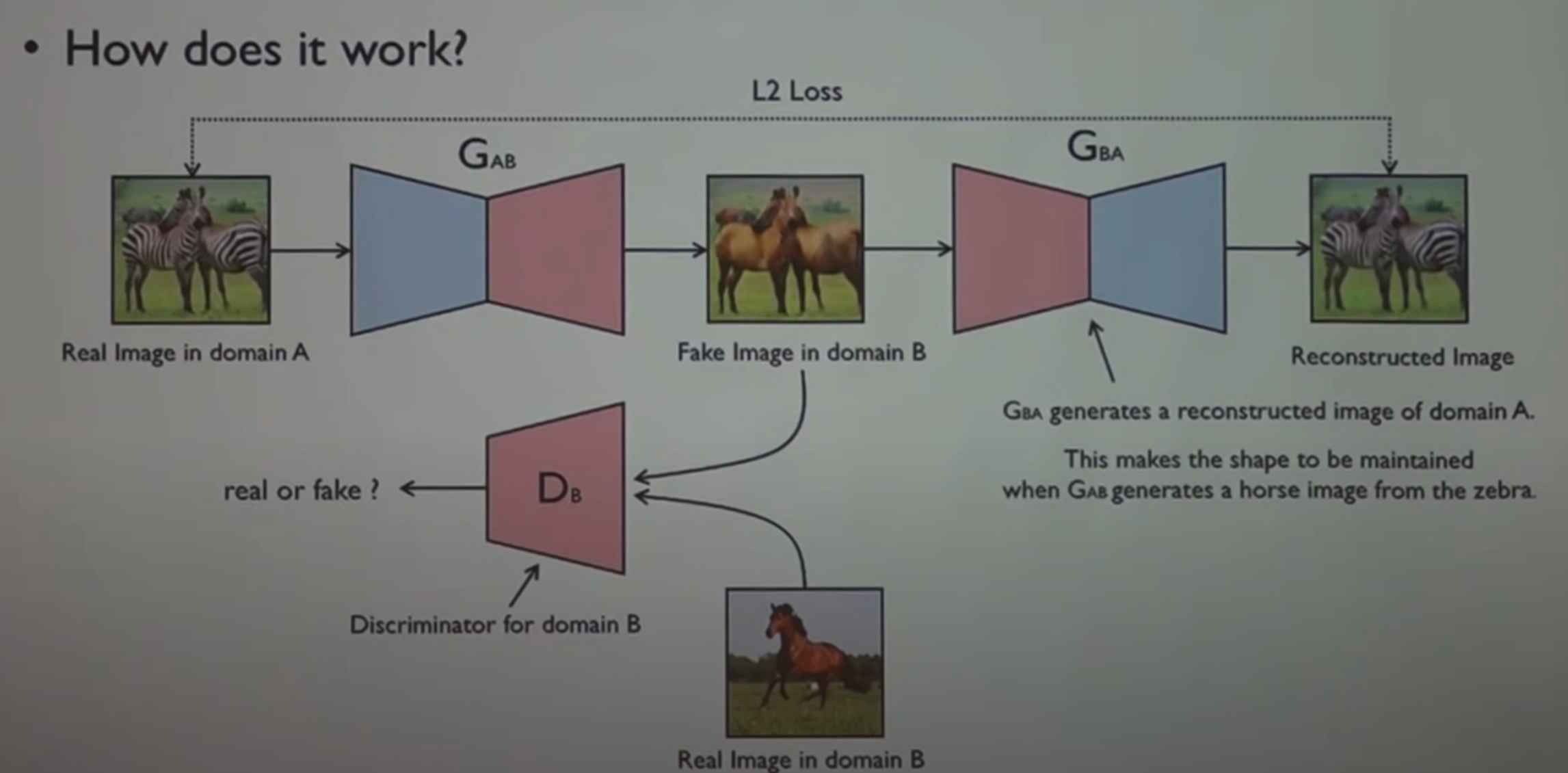
https://github.com/yunjey/mnist-svhn-transfer
-stackGAN



BEGAN (boundary equilibrium) - 기존 gan은 loss 가 없는데 (노답이라) convergence measure 롤 세워서 그걸 loss 처럼 썼다. (경험론적으로 설정한 점이 다소 있음)

stride 를 필터마다 다르게 주는 건 어떠냐는 질문이 들어왔었다.
-seq2seq 활용가능성에 대해서 번역 fake korean discriminator 같은 이야기 하시며 <끝>
- http://proceedings.mlr.press/v48/reed16.pdf
Generative Adversarial Text to Image Synthesis (GATIS )라고 함.
-Auxiliary Classifier ACGAN
inception score
BEGAN (boundary equilibrium) - 기존 gan은 loss 가 없는데 (노답이라) convergence measure 롤 세워서 그걸 loss 처럼 썼다. (경험론적으로 설정한 점이 다소 있음)
----
1. GAN을 봤다. 이안굳펠로는 굉장히 겸손하게 이것이 기존 마르코프 chain을 쓰는 형식의 모델들보다 낫지는 않아도 마르코프체인을 뺀 것이 유의미하고 또한 경쟁할 만 한 것이라고 했다. D와 G를 만들어 한 스텝에서 하나씩 학습시켰고, (G만 너무 학습되면 G가 input에 쏠려 분산이 낮아지는데 이를 Helvetica scenario 라고함), 그렇게 함으로써 D의 분포는 점점 찐데이터분포와 G데이터분포를 분류하게 되고 그렇게 함으로써 G데이터분포가 찐데이터에게 수렴하도록 유도된다는 것을 보여줬다. (08:13)2. GATIS를 보자.
'AI' 카테고리의 다른 글
| StyleCLIP에 대한 논문을 봤다. (0) | 2023.04.30 |
|---|---|
| DeltaEdit에 관한 논문을 봤다. (0) | 2023.04.29 |
| Stable Diffusion 을 이해해보자. (0) | 2023.04.12 |
| Difference between AE and VAE (0) | 2023.02.07 |
| DetectoRS: 재귀적 특징 피라미드와 교환가능한 Atrous Convolution 을 이용한 객체 검출 (0) | 2020.07.29 |
- Total
- Today
- Yesterday
- /var/log/fontconfig.log
- /var/log/faillog
- Source-free unsupervised domain adaptation
- batch란
- 전이학습
- Group Acitivty Recognition
- DetectoRS
- Arbitrary image stylization
- alternatives.log
- tensorflow convert
- 샴네트워크
- tf2to1
- 1-stage detection
- 첫논문
- Deformable Convolutional Networks
- Deformable Part Model
- StyleCLIP
- textual guidance
- /var/log/tallylog
- 도메인 어댑테이션
- torchmodel
- max-margin_loss
- ctfloader
- neural network applications
- /var/log/alternatives.log
- Chatgpt4
- TransferLearning
- 딥페이크탐지
- tf version porting
- yolov3 #tensorflow_convert
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |