YOLO v1~v8까지 정리 해보자
ChatGPT 4.0한테 물어봤는데 아직 검증은 안했다.
--
욜로는 You Only Look Once 라고 해서 Object Detction 방법론 중에 하나이다.
객체 검출 방식에는 박스영역를 다음 classification 을 진행하는 것(2-stage)과 이를 동시에 진행하는
1-stage 가 있다. (정확하게는 박스&박스내 객체 탐지 여부인 confidence와 class probability map을 병렬적으로 따로 진행함)
YOLOv1
- 발표 연도: 2015
- 개발자: Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi
- 소속 기관: University of Washington, Allen Institute for AI, Facebook AI Research
- 특징: YOLO는 이미지를 그리드로 나누고, 각 그리드 셀마다 바운딩 박스와 클래스 확률을 예측합니다. YOLOv1은 실시간 처리가 가능하며, 전체 이미지를 한 번에 보기 때문에 배경 오류가 적지만, 작은 객체 탐지에는 약점이 있습니다.
YOLOv2 (YOLO9000)
- 발표 연도: 2016
- 개발자: Joseph Redmon, Ali Farhadi
- 특징: YOLOv2는 YOLOv1에 비해 속도와 정확도를 모두 향상시켰습니다. Anchor boxes를 도입해 다양한 형태의 객체를 더 잘 탐지할 수 있게 되었고, 9000개 이상의 객체 카테고리를 탐지할 수 있는 능력을 갖추었습니다.
anchor box는 전에 1-stage 에서 설명했다.
2021.03.01 - [AI/Baseline] - 1-stage detector 객체 검출법
YOLOv3
- 발표 연도: 2018
- 개발자: Joseph Redmon, Ali Farhadi
- 특징: YOLOv3는 YOLOv2 대비 탐지 정확도를 크게 향상시켰습니다. 이 버전에서는 3개의 다른 크기의 feature map에서 탐지를 수행하여 작은 객체의 탐지 성능을 개선했습니다.
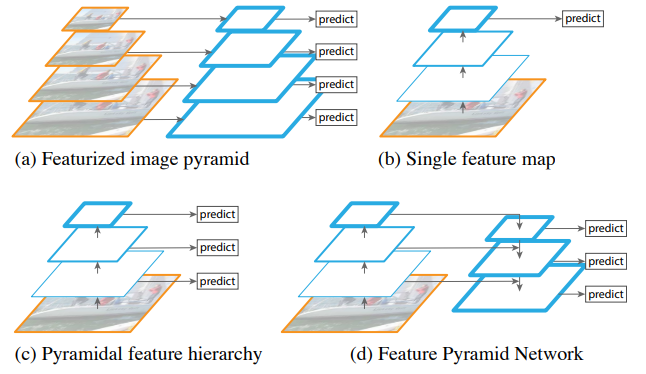
-이 부분은 Feature pyramid network 를 말하는 것 같은데 아직도 블로그에서 정리하지 않은 것을 보고 깜-짝 놀라버렸다 세상에 ㅠㅠ 얼른 정리 해야겠다.
2021.07.11 - [Computer Architecture/Baseline] - Feature Pyramid network
3년전이라 까먹을만 하다.
그런데 Yolov3의 featuer map과 FPN은 유사한목적(다양한 크기의 객체를 효과적으로 탐지)으로 고안되었지만 약간의 차이가 있다고 한다. (출처 : https://songminkee.github.io/studyblog/object%20detection/2020/10/16/YOLOv3.html ) 에서도 FPN과 같이~ 라고 했었음.
YOLOv3에서 말하는 이미지 처리과정에서 자연스럽게 생성되는 세가지 다른 해상도 feature map이란 게 무슨 뜻이야? fPN과 yolov3의 차이를 표로 그려줄수 있어?
FPN과 YOLOv3의 차이점을 정리한 표는 다음과 같습니다:
FPN YOLOv3| 구조적 차이 | 하위 레벨의 feature map을 상위 레벨로 업샘플링하고 결합하여 새로운 feature pyramid를 생성 | 이미지를 처리하는 과정에서 네트워크의 다른 지점에서 자연스럽게 생성되는 세 가지 다른 해상도의 feature map을 사용 |
| 용도 | 다양한 네트워크 구조에 통합 가능한 일반적인 방법으로 객체 탐지 및 세그멘테이션 작업에 사용 | YOLOv3 알고리즘 내에서 특정하게 사용되는 전략 |
| 멀티스케일 특징 추출 방식 | 명시적으로 다양한 해상도의 feature map을 업샘플링 및 결합 | 네트워크가 깊어질수록 점차적으로 줄어드는 feature map의 해상도를 활용 |
| 상하 피라미드 통합 | 예, 상위 레벨의 feature map을 하위 레벨로 업샘플링하여 정보를 통합 | 아니오, 각 feature map은 독립적으로 객체를 탐지하는 데 사용됨 |
YOLOv3에서 말하는 "이미지 처리 과정에서 자연스럽게 생성되는 세 가지 다른 해상도의 feature map"은 YOLOv3의 네트워크 구조가 깊어질수록, 여러 계층에서 추출되는 다양한 크기의 feature map을 의미합니다. 이러한 feature map은 네트워크 내부에서 자연스럽게 발생하는 구조의 결과물이며, 각각 다른 크기의 객체를 탐지하는데 최적화되어 있습니다. 이는 FPN에서 사용되는 방식과는 구조적으로 다르며, FPN이 명시적인 상하 통합 과정을 거치는 반면, YOLOv3는 각각의 feature map을 독립적으로 사용합니다

YOLOv4
- 발표 연도: 2020
- 개발자: Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao
- 특징: YOLOv4는 속도와 정확도의 균형을 더욱 개선하였습니다. CSPDarknet53을 백본으로 사용하며, 다양한 최신 기술들(Mish 활성화 함수, Cross-stage partial connections 등)을 통합하여 높은 프레임 속도에서도 높은 정확도를 달성합니다.
-이제부터 내가 안 쓴 방법론이다. 아니, 4까지는 썼던가? CSPDarknet53, Mish 활성화, Cross-stage partial connections 등을 알아보자. 이후는 딱히 정보값이 낮아서 접기함.
YOLOv5
- 발표 연도: 2020
- 개발자: Glenn Jocher (Ultralytics)
- 특징: 공식 YOLO 시리즈에 포함되지는 않았지만, YOLOv5는 사용의 용이성과 속도, 정확도 면에서 주목받았습니다. PyTorch 기반으로 구현되었으며, 다양한 크기의 모델이 제공됩니다.
YOLOv6
- 발표 연도: 2022
- 개발자: Meituan
- 특징: YOLOv6는 높은 성능과 효율성을 강조합니다. 실시간 성능이 뛰어나며, 여러 최신 기술을 통합하여 더욱 정확한 객체 탐지가 가능합니다.
YOLOv7
- 발표 연도: 2022
- 개발자: Wong Kin Yiu et al.
- 특징: YOLOv7은 YOLO 시리즈 중 하나로, 여러 최신 기술과 개선 사항을 통합하여 뛰어난 정확도와 속도를 제공합니다. 이 버전은 특히 다양한 환경에서의 강인성을 개선했습니다.
YOLOv8
- 발표 연도: 정보 업데이트 필요
- 개발자 및 특징: YOLOv8에 대한 구체적인 정보는 제가 마지막으로 업데이트 받은 시점에서는 제공되지 않았습니다. YOLO 시리즈는 계속해서 발전하고 있으며, 각 버전마다 기술적 진보와 성능 향상에 초점을 맞추고 있습니다.
YOLO 알고리즘의 각 버전은 객체 탐지 분야에서 중요한 이정표를 설정하며, 컴퓨터 비전 연구와 응용에 있어 지속적으로 기여하고 있습니다.
오늘부터 차츰차츰 수정해보자.