Attention 다시 보기
2023.05.19 - [AI/Baseline] - Attention 에 대한 논문을 봤다.
Attention 에 대한 논문을 봤다.
GRU에 대해서도 이해하고 싶었는데 그건 그냥 유튜브 영상을 보기로 했다. https://aistudy9314.tistory.com/63 https://www.youtube.com/watch?v=jbf_k7b16Vc https://arxiv.org/abs/1706.03762 Attention Is All You Need The dominant sequenc
cho-akashic-records.tistory.com
오래간만에 다시 봤는데 하나도 기억이 안난다. 하하
오늘의 개념 정리
- CTC(Connectionist Temporal Classification) https://en.wikipedia.org/wiki/Connectionist_temporal_classification
-가변적인 Seq 문제를 해결하기 위해 LSTM과 같은 순환신경망(RNN)을 훈련하기 위한 일종의 NN 출력 및 관련 점수 함수 라고 한다. scroing 과 출력에 관한 함수로 2006년에 소개되었다.
-CTC가 적용된 NN에는 은닉 마르코프 모델이 있다고 한다. (HMM)
--아래는 블로그 https://blog.naver.com/sogangori/221183469708
- CTC는 학습데이터에 클래스 label만 순서대로 있고 각 calss location 은 어디인지 모르는 unsegmented sequence data의 학습을 위해 사용하는 알고리즘이다.
(이건 내일 보자 https://distill.pub/2017/ctc/)

LSTM(Long short-Term Memory) https://towardsdatascience.com/lstm-recurrent-neural-networks-how-to-teach-a-network-to-remember-the-past-55e54c2ff22e
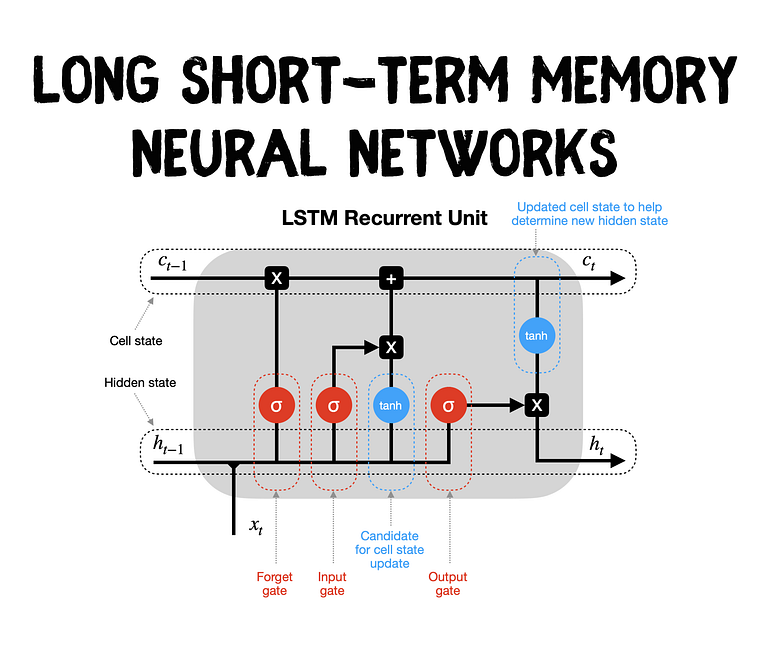
내 기억으로는 메모리셀이 캐시급으로 이전의 셀만 많이 기억하고 좀 오래된 요소는 기억을 못하니까 그걸 완화하려고 만든 걸로 알고 있다. 고급버전의 RNN의 두가지 버전은 LSTM과 GRU가 있다고 한다.
- GRU(Gated Recurrent Units) https://wikidocs.net/22889

- Seq2Seq (https://wikidocs.net/24996)
- 크게 Encoder / Decoder 모듈로 구성된다. 인코더는 Input의 모든 단어를 순차적으로 입력받아 압축하여 하나의 벡터를 만드는데 이를 Context vector라고 한다. 그리고 context vector는 디코더로 전송된다.

- End -to-end memory network(https://velog.io/@jeewoo1025/What-is-end-to-end-deep-learning)
: 입력에서 출력까지 파이프라인 네트워크 없이 신경망으로 한 번에 처리한다는 뜻이라고 한다.

- Multi head attention https://www.blossominkyung.com/deeplearning/transformer-mha

https://youtu.be/qrpyswoATQ8?si=_KhzEK1YvRQreOUo
이걸 보고 영상을 보고 느낀게, 일단 글자로도 내가 이해했닫고 보기가 힘들고, 그림으로 내가 그릴 줄 알아야 됨. 적어도 CNN은 내가 얼 추 그릴 줄 앎.