
DragGAN을 봤다.
https://vcai.mpi-inf.mpg.de/projects/DragGAN/
https://arxiv.org/pdf/2208.12408.pdf
내가 하고 싶은 text driven image manipulation 은 너무 어려우니까 이걸로 우회할까 생각중이다. 갑자기 자신감이 뚝뚝 떨어졌다. 과제나 할까? 흑..

DragGAN
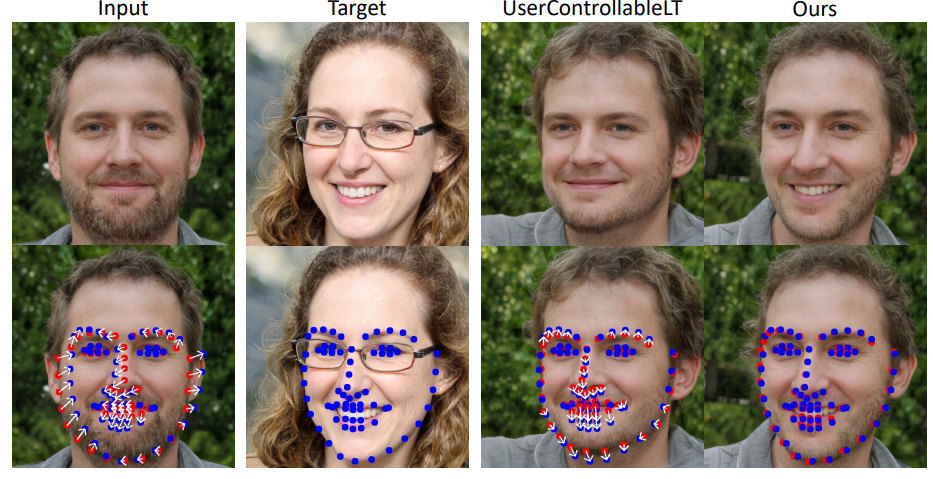
- 기존 UsercontrollableLT의 문제는 2개가 있었다.
- 1) 점 하나이상은 제어가 어렵다? ( the contorl of more than one point, which their approach does not handle well
- 2) 제어하는 포인트에 정확하게 접근하지 못한다. 본 논문은 이걸 해결했다고 한다.
-dragGAN은 RAFT같은 추가네트워크에 의존하지 않아요.
*RAFT란? (by chatGPT)
-"Robust Adaptive Fusion Tracking"의 약자입니다. RAFT는 컴퓨터 비전 분야에서 객체 추적을 위한 심층 학습 기반의 알고리즘입니다. 이 알고리즘은 영상에서 움직이는 객체를 식별하고 추적하는 데 사용됩니다. RAFT는 기존의 추적 알고리즘에 비해 더 높은 정확도와 안정성을 제공하기 위해 신경망 아키텍처와 광범위한 학습 데이터를 활용합니다. RAFT는 움직임, 변형, 가려짐과 같은 객체 추적을 어렵게 만드는 도전적인 상황에서도 강력한 추적 성능을 발휘할 수 있습니다. 이를 통해 RAFT는 컴퓨터 비전 응용 프로그램에서 실시간 객체 추적과 움직임 분석에 사용될 수 있습니다.
- 학습은 RTX 3090 하나로만 진행했다!
- 이를 통해 사용자가 원하는 출력을 얻을 때까지 다양한 레이아웃을 빠르게 반복할 수 있는 실시간 대화형 편집 세션이 가능합니다.
2. 관련 연구
- 2.1 Generative Models for Interactive Content Creattion
- 제어가능한 이미지 합성에 있어서 대부분 현존하는 방법들은 GAN이나 Diffusion 모델을 쓴다.
- 조건없는 GAN : styleGAN같은 GAN모델들은 곧바로 생성된 이미지를 수정할 수 없다.
- #근데 StyleGAN이야 말로 조건 GAN아닌가 .. :3 #이것도 GPT한테 물어봤더니, 여기서 말하는 contional 이라는 것은 편집기능 여부에 초점을 맞춘 단어라고 한다. (원래 conditional 맞다고 함)
- 조건적인 GAN : 네트워크가 segmentation map이나 3D변수같은 조건적인 입력을 받는다. 조건전분산을 쓰는대신 editGAN 같은게 있었다. 얘가 처음으로 joint distribution 과 segmenation map을 활용해 map에 상응하는 새로운 이미지를 연산해냈다.
- 편집 불가능한 GAN들을 이용해 편집하기 위해서는 이미지를 생성한 latent vector를 조작하는 수밖에 없다. 이런 방법이 여러개 제안되었다. 기존의 3D모델 혹은 실존하는 annotation 파일로부터 지도학습 하는 방식들 말이다.
- 또다른 방법으로는 비지도 학습을 통해 latent 공간에서 semantic한 dirction 을 찾는 것이다. 최근에는 "blob"이나 히트맵 같은 intermediate 를 도입해 객체의 위치를 조절하는 방법도 제안되었다.
- GANWarping[2022] : 점기반 편집을 스지만 주로 out-of-distribution 의 이미지 수정만 가능해다. 몇 개의 warped image 들을 수정시할 수 있었지만 이 방식이 real 하게 보이지는 않았다. 또한 이 방법으로 객체의 3D식으로 자세를 변경할 수도 없었음.
- 3D-award GANs
- 3d 제어를 하는 GAN이 있기는 했다. 이런 방법들은 모델이 3D 모델을 직접적으로 표현하는방식으로 렌더링하는데, 논문의 접근법과 달리 이런 방식으로는 global pose 나 lighting(조명말하는듯)의 편집이 한정되어있었다. 우리꺼는 점기반 방식으로 공간속성에 대해 세밀한 표현도 가능함!
- Diffusion
- 디퓨전 모델은 랜덤하게 샘플링한 noise를 반복적으로 제거하여 real한 이미지를 생성한다. 얘네들은 text 기반으로 이미지를 생성하는데, 자연어는 세밀한 제어를 제공하지 않느다. 그리고 모든 text-conditional 방법들은 고수준의 semantic한 편집이 제한되어있다.
- 그리고 디퓨전은 노이즈제거에 여러단계가 필요하기 때문에 속도도 느리다. 이 문제를 개선하기 위해 샘플링을 효과적으로 하려고 하고 있지만 여전히 GAN이 훨신 효율적이다.
- 2.2 Point tracking
- 기존에는 hand-crafted criteria[2010] 방식으로 두 개의 이미지 사이에 모션을 예측했다.
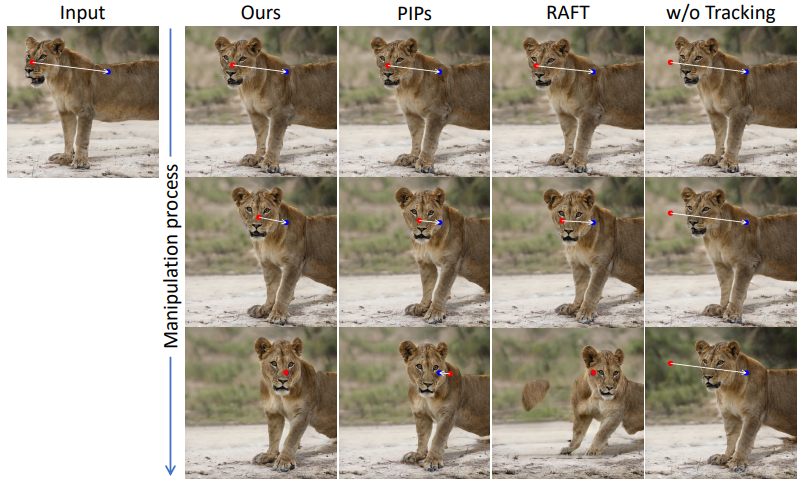
- 요즘에는 RAFT(2020) 를 쓴다. (위에 있음) 이와 유사한 방식으로 particle video란 방식으로 여러 프레임에 걸친 정보를 고려해 PIPs라는 새로운 점 추가 방식을 발견하기도 했음. +더 장거리 추적 가능함.
- 그러나 우리 연구는 따로 앞서 언급한 접근방식이나 추가신경망을 사용하지 않고도 추적을 수행했다. 이전의 작업에서 discriminative feature in semantic segmenation 을 보여주기도 했지만 점기반 편집문제(point-based editing)를 discriminative GAN과 과 연결해 연구한 것은 우리가 최초다.
3. 방법
- 52 dimensional latnet code z 가 w 512랑 매핑되었다. w의 공간은 보통 W와 참조된다. w는 생성자 G로 전달되어 출력이미지 I=G(w)를 생성한다. 이 과정에서 w는 복사되어 생성자 G의 다른 레이어로 보내지고 다양한(different) 수준의 attributes를 제어한다. 또는 각 레이어에 대해 different w를 쓸 수 있으며 이 경우 입력은 𝒘 ∈ R 𝑙×512 = W+ 가 된다.
- l은 레이어의 수이고 이 덜 제약을 받는 W+공간은 이제 더 표현력있게 보일 것이다. 생성자 G는 저차원 잠재공간에서 훨씬 더 높은 차원의 이미지 공간으로의 매핑을 학습하므로, image manfold를 모델링하는 것으로 볼 수 있다.
- 3.1 상호적인 점기반 조작
- 업데이트 : 이미지의 객체가 약간 이동한다. 모션 supervision 단계는 각 제어점을 타겟방향으로 이동시키나, 정확한 길이는 complex optimization 의 동태와 대상, 부위에 따라 달라진다. 따라서 우리는 제어점의 위치를 대상점으로 갱신시킵니다. 이 과정이 필요한 이유는 사자의 코로 예를 들어봅시다, 만약 제어점이 제대로 추적되지 않는다면 다음의 supervision 단계에서 사자의 얼굴로 잘 못 supervised 될 것입니다. 바라지 않는 결과로 유도하는 것입니다. 추적후에 새로운 제어점과 latent code 들을 기반으로 위의 최적화 단계를 반복합니다. 보통실험에서 30-200정도 반복이 소요됩니다. 사용자는 최적화를 중간에 멈출수 있습니다.
- 3.2 Motion supervision
- 이 연구에서는 motion supervision loss를 설명한다. 얘는 추가 NN에 의존을 안한다. 주요 아이디어는 생성자의 중간 피처가 매우 구별적이어서 단순한 loss로도 모션을 supervise할 수 있다는 것이다. StyleGAN2(이런것도 있었어?) 피쳐맵 F 을 bilinear 보간을 통해 최종 이미지와 동일한 해상도로 크기를 조정한다.
- 그림 3을 보라, 제어점 p_i를 대상점 t_i로 이동시키기 위해 p_i(빨간원)를 주변의 t_i방향으로 small step 이동시키는 것이 아이디어이다.(파란원)
- 𝒑𝑖와의 거리가 𝑟1보다 작은 픽셀을 Ω1(𝒑𝑖, 𝑟1)로 표시하면, 우리의 모션 감독 손실은 다음과 같습니다:
#이부분을 다시 이야기하자면 p입장에서 이미지를 재생성하는데 이제 p->t로 하여금 loss 를 산출한 다는 것음 재생성하면서 점점 p가 t에 가까워지도록 유도한다는 것임 . 그 비교가 어디서 이뤄지냐 하면은 latent code 에러 이뤄진다는 것! 으로 이해했음. (image manifold를 말하는 것도 이 때문이라고 생각)
- 각 모션 감독 단계에서 이 손실은 𝒘의 최적화를 한 단계에 사용합니다. 𝒘은 W 공간이나 W+ 공간에서 최적화할 수 있으며, 사용자가 보다 제약이 있는 image manifold를 원하는지 여부에 따라 선택할 수 있습니다.
- W+ 공간은 분포 범위 밖의 조작(예: 그림 16의 고양이)을 더 쉽게 달성할 수 있기 때문에 본 연구에서는 편집 가능성을 높이기 위해 W+를 사용합니다. 실제로 이미지의 공간적 속성은 첫 6개 레이어(#styleGAN2의 그거 말하는듯)의 𝒘가 주로 영향을 미치는 반면, 나머지 레이어는 외관에만 영향을 미칩니다.
- 따라서 스타일 혼합 기술[Karras et al. 2019]에서 영감을 받아 우리는 나머지를 고정시키고 첫 6개 레이어의 𝒘만 업데이트하여 외관을 보존합니다. 이 선택적 최적화는 이미지 콘텐츠의 원하는 작은 움직임을 유발합니다.
3.3 point tracking
이전의 motion supervision 은 결과로새 latent code w 와 새 피쳐맵 F, 새 Image I 를 산출한다. motion supervision 단계에서는 제어점의 정확한 새 위치를 제공하지 않기 때문에 우리는 각 제어점 p_i의 각 대응지점을 추적하도록 업데이트 하는 것을 목표로 삼았다. 일반적으로 포인트 추적은 optical flow 추정 모델이나 입자비디오 접근법(particle video)을 이용한다.
그러나 이러한 추가모델은 효율성을 저하시킬 수 있으며 특히 현재 GAN의 핵심아이디어는 GAN의 구별적 측징이 밀도가 correspeondence 를 잘 잡아냄으로 특징 패치네에서 제일 근접하는 이웃을 검색하여 추적을 효과적으로 수행할 수 있다는 장점이 있다.
특징 맵은 256 × 256의 해상도를 가지며, 필요한 경우 이미지와 동일한 크기로 이중 선형 보간됩니다. 이는 우리의 실험에서 정확한 추적을 수행하기에 충분합니다. 이 선택에 대해서는 4.2절에서 분석합니다.
- 실험들


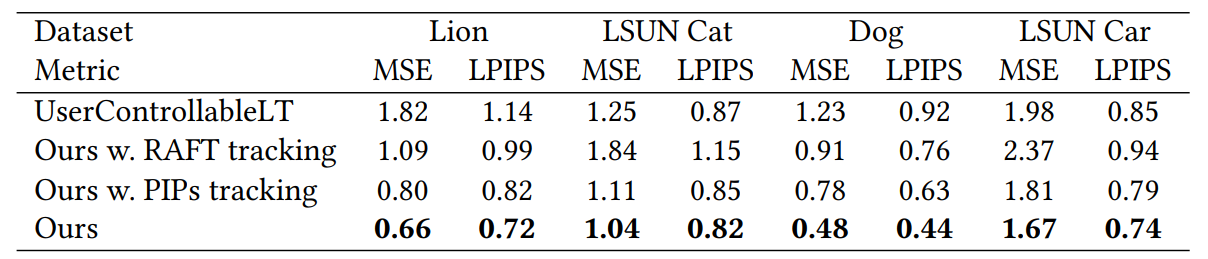

-나머지는 생략-
5. 결론 .
DragGAN은 직관적인 포인트 기반 이미지 편집을 위한 인터랙티브 접근 방식을 제시했습니다. 우리의 방법은 사전 훈련된 GAN을 활용하여 사용자의 입력을 정확하게 따르면서도 실제적인 이미지의 매니폴드 상에 머무를 수 있는 이미지를 합성합니다. 많은 이전 접근 방식과 달리, 우리는 도메인 특정 모델링이나 보조 네트워크에 의존하지 않는 일반적인 프레임워크를 제시합니다. 이를 위해 두 가지의 새로운 요소를 활용합니다. 여러 개의 핸들 포인트를 대상 위치로 점진적으로 이동시키는 잠재 코드의 최적화 및 핸들 포인트의 궤적을 정확하게 추적하는 포인트 추적 절차입니다. 이 두 가지 구성 요소는 GAN의 중간 특징 맵의 식별력을 활용하여 픽셀 정밀도의 이미지 변형과 인터랙티브 성능을 제공합니다. 우리의 접근 방식이 GAN 기반 조작에서 최신 기술을 능가하며, 생성적인 사전을 활용한 강력한 이미지 편집을 위한 새로운 방향을 열어준다는 것을 입증했습니다. 향후 연구 방향으로는 포인트 기반 편집을 3D 생성 모델로 확장할 계획입니다.
이후에 내가 봐야할 것
- controlableLT (2022.08)
- Diffusion / Diffusion2 도 있는걸로 알음
- StyleGAN, StyleGAN2
근데 이제 오늘부터는 과제를 좀 해야겠다.