Deformable Convolutional Networks(DCN)
2021.02.22 - [AI/Baseline] - Detecto RS를 이해하기 위한 기반 다지기
Detecto RS를 이해하기 위한 기반 다지기
DetectoRS가 너무너무 어렵기 때문에 하나하나 이해해 보기로 했다.
cho-akashic-records.tistory.com
여기서 맨 오른쪽에 있었던 Deformable Convolution Network 에 대해서 알아보자!
먼저 내가 receptive field 개념이 헷갈리기 때문에 이것부터 집고 넘어가기
receptive field란 출력 레이어의 뉴런 하나에 영향을 미치는 입력 뉴런들의 공간 크기
w, h, z 에서 kernel을 통해 output이 나오면, 그 아웃풋의 뉴런 한 개가 얼만큼의 input 영역을 수용했는지를 나타낸다.
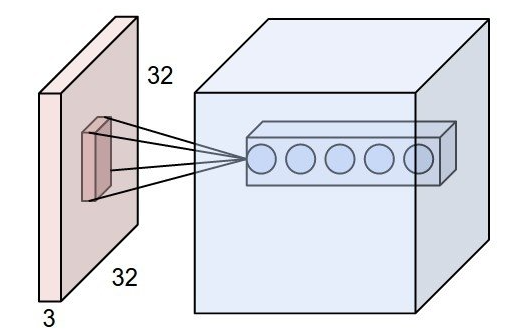
1x1 convolution을 하면 receptive filed 크기는 고정한 채로, depth(z) 의 size를 조절(감소/증가) 시킬 수 있다.
떨리는 마음으로 논문을 보면 Abstrct에 이렇게 적혀있다.
(번역) CNN이 여지껏 모델 geometric 변환에 제한적이었는데, 이는 모델을 build할 때 geometric 구조가 고정되어있기 때문입니다. Deformable Convolutional Networks에서는, CNN의 transformation 모델링 성능을 끌어내기 위해 2개의 새 모듈을 소개합니다. 이름붙이자면 deformable convolution 과 deformable RoI pooling입니다.
둘다 spatial sampling을 augmenting 하는 idea에서 기반했습니다. 영역을 샘플링 할 때 additional offsets을 사용함으로써 target task로 부터 offset을 학습하는 것입니다. (additional offset 별도의) 지도(학습)없이 수행됩니다.
이 모듈들은 현존하는 CNN을 능가(replace)할 수 있습니다. standard back-propagation 을 쓰는 end to end training으로도 학습됩니다. (후략) 객체검출이나 semanticsegmantation 같은 정교한 작업에 효과적인 방법은 deep CNN에서 dense spatial transformation 을 학습하는 것입니다.
여기서 말하는 deformable convolution 과 deformable RoI pooling에 대해 알아보자.
- convolution 유닛은 고정된 위치에서 input feature amp을 샘플링한다. pooling 층은 spatial 해상도를 fixed ratio 로 감소시킨다. RoI pooling 층이 RoI를 fixed spatial bins 등으로 조각낸다. 그 내부 메커니즘의 결핍요소가 geometric transformation 다루는 것을 어렵게 합니다. 이 문젠눈 눈에 띄게 발생합니다.
- 예를들어, 같은 CNN층에서는 모든 activation unit의 receptive filed size가 같습니다. 이건 이상적인 high level CNN 과는 거리가 있습니다. CNN은 공간위치에 대한 의미를 인코딩해야 합니다. (그런데 그렇게 못하고 있다는 뜻임)
- 왜냐하면 정밀한 위치파악을 통한 시각적 인식의 바람직한 길은, 객체들의 다른 위치들이, 다양한 scale과 deformation, scale혹은 recptive filed size 의 adaptive determination에 해당(하는 방법으로 구)할 수 있기 때문입니다.

(기존 CNN이 convolution 과 pooling을 반복한다면) deformable convolution 은 여기서 convolution 이 하나 더 존재한다.

학습과정에서 convolution 이 하는 일이 두개다. output 특징을 만드는 convolution kernel과 offset을 정해주는 convolution kernel, 이 두 개를 동시에 할 수 있다.
아래 그림은 convolution filter 의 sampling 위치를 보여주는 예시이다. 붉은색 점들은 deformable convolution filter 에서 학습한 offset 을 반영한 sampling location 이며, 초록색 사각형은 filter 의 output 위치이다. 일정하게 sampling pattern 이 고정되어있지 않고, 큰 object 에 대해서는 receptive field 가 더 커진 것을 확인 할 수 있다.


"
RoI (Region of Interest) pooling 은 크기가 변하는 사각형 입력 region 을 고정된 크기의 feature 로 변환하는 과정이다.
RoI pooling이란?(접기) 24.02.25
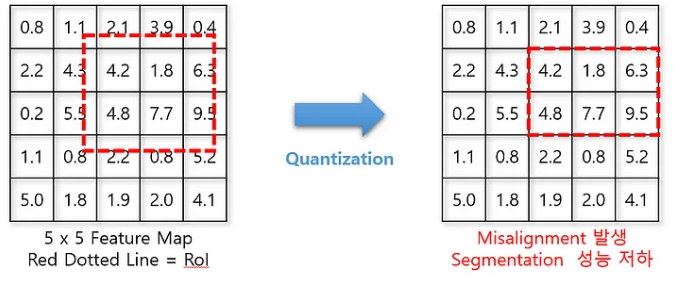
헷갈리겠다고 적은 것은 roi pooling 보다는 RoI algin인 것 같은데 pooling을 마저 말하자면,
-다양한 사이즈의 region 에서 고정된 크기의 feature을 산출하려고 만든 방식이다, 그림에서 큰사람이나 작은 사람이나 같은 feature로 입력해 model Inference를 진행할 수가 있다.(개인적으로 보면 물리적으로 쑤셔넣은게 아닌가 싶다.) 그림에서 보다시피 misalignment가 발생한다.
-RoI algin 이란.
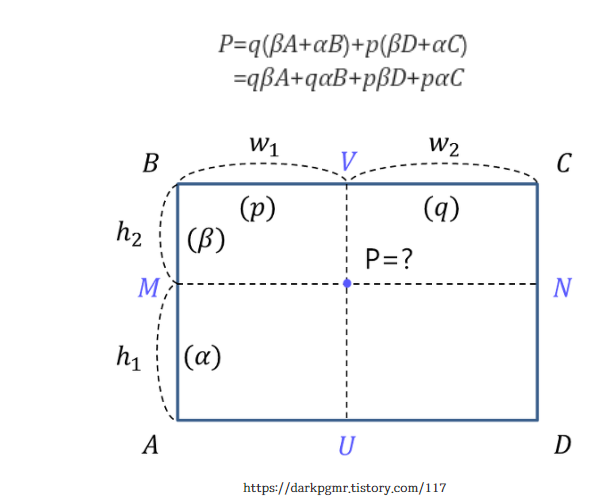
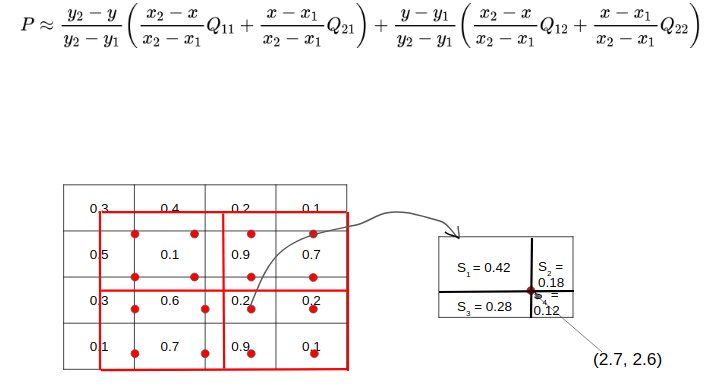
-이제 segmentation 을 위해 위치를 잘 찾을 필요가 있다. misalignment는 용납되지 않는다. 이제 선긋지 않고 보간방식으로 짐작한다. 양쪽에 0과 10 값이 있다면 그 사이에 123456789가 있을 거라는 거리상의 짐작을 하는 방법을 만한다.
-임의로 찍은 선들은 4개의 영역에 걸쳐져 각칸의 feature value를 참조해 보간값을 구할 수 있을 것이다.
이는 일반적은 RoI Pooling layer 와 offset 을 학습하기 위한 layer 로 구성된다. 한가지 deformable convolution 과 다른 점은, offset 을 학습하는 부분에 convolution 이 아니라 fully connected layer 를 사용한 것이다. 또한 마찬가지로 학습 과정에서 offset 을 결정하는 fc layer 도 backpropagation 을 통해 학습된다.
아래 그림에서 노란색 입력 RoI 에 대해 붉은색 deformable RoI pooling 결과를 보여준다. RoI 에 해당하는 붉은 사각형의 모양이 object 형태에 따라 다양한 형태로 deformation 되는 것을 확인 할 수 있다.
"
(인용)
그래서 offsetlayer가 무엇을 변화시켰느냐(수식편)

결론 :
- deformable은 사각형의 shape을 없애고 학습한다.
- deformable이라고 부르는 이유는 기존 CMN이 일정패턴을 가정하고 있어서, '복잡한' transformation은 대처를 못하는데, 그것이 구체화 되면 receptive field의 영역이 항상 같아지는 형태를 보인다. 그래서 Deformable에서는 해당 수용영역에 대해서 form 없애기 위해, offset layer를 추가함으로써 입력 x에 얼만큼의 offset을 추가할지를 학습한다. 이렇게 하면 flexible한 영역에서 특징을 추출할 수 있다고 제안한다.
- 여기서 말하는 offset이 가중치는 아니고, y = ax + b가 y= a(x+offset) + b 가 되는 것이고 이 offset을 학습하는 것 같다.
- offset을 통해 object안에 점을 찍는다. convolution학습을 진행하며 offset을 학습시킬 수 있다.
일단 개괄적인 것은 여기까지 ,(마지막 부분은 소화를 잘 못시켰다. 되새김질 하러 와야겠다)
-20210711 되새김질왔다. 아직 모르겠다.
출처 :
1. receptive field(수용영역, 수용장)과 dilated convolution(팽창된 컨볼루션)
eehoeskrap.tistory.com/406m.blog.naver.com/PostView.nhn?blogId=sogangori&logNo=220952339643&proxyReferer=https:%2F%2Fwww.google.com%2F
2. [Object Detection] Deformable Convolutional Networks https://eehoeskrap.tistory.com/406
3. Deformable Convolutional Networks arxiv.org/pdf/1703.06211.pdf
4. DCN 리뷰(2017) https://deep-learning-study.tistory.com/575
5.https://medium.com/@parkie0517/fast-r-cnn-논문리뷰-roi-pooling-layer와-truncated-svd-a1147f7267be