AI
Adaptive Aggregation Networks for Class-Incremental Learning
아인샴
2024. 5. 28. 16:07
목적 : sequential invariant 한 DA 아이디어를 찾아야한다.
선정 이유 : CVPR 21' cite 140; adaptave한 networks에 stable하고 xx한 block을 활용할 예정이라고 했다.
- experiments 전까지만 읽으면 될 것 같다.
Abstract
- CIL목적 : class 수가 점점 증가하는 분류모델 학습
- 문제 : high-plasticity model은 새로운 class를 학습할때 old class를 잊고 high-stability모델은 새 클래스 학습이 어려운 딜레마
- 해결전략 :
- "Adaptive Aggregation Networks"(AANets) ;residual level마다 2종류의 residual block을 가진 Resnet 기반의 네트워크;
- stability와 plasticity를 dynamic하게 조정하기 위해 이 둘의 가중치를 조절한다.
- 실험 : CIFAR100, ImageNet(-subset) 으로 수행했고 성능 향상시켰다.
Introduction
- catastrophic forgetting : 모델이 이전데이터에서 획득한 지식을 무시(override)할 수 있으며, 이전 지식은 재생(replay)할 수 없다는 문제; 이를 해결하기 위해, 모든 old data를 저장하는 대신 exemplar set을 활용했으나 old/nes class의 심각한 data imbalence 이슈가 발생했고, 안정성이 높을 수록, large number of samples의 새로운 클래스를 학습하는게 어려웠다. 기존 CIL전략들은 그림1 (a),(b)와 같이 old class에 대한 small exemplar 의 imbalanced dataset 학습이 있었고, 최근에는 모든 클래스로부터 exemplars를 추출해 balanced subset을 쓰는 fine-tuning하는 방법이 있다. 하지만 25 phase 이후의 모델을 사용할 때, LUCIR과 Mnemonics는 ImageNet dataset에서 초기 50개 class를 30%,20% 씩 "잊었다".
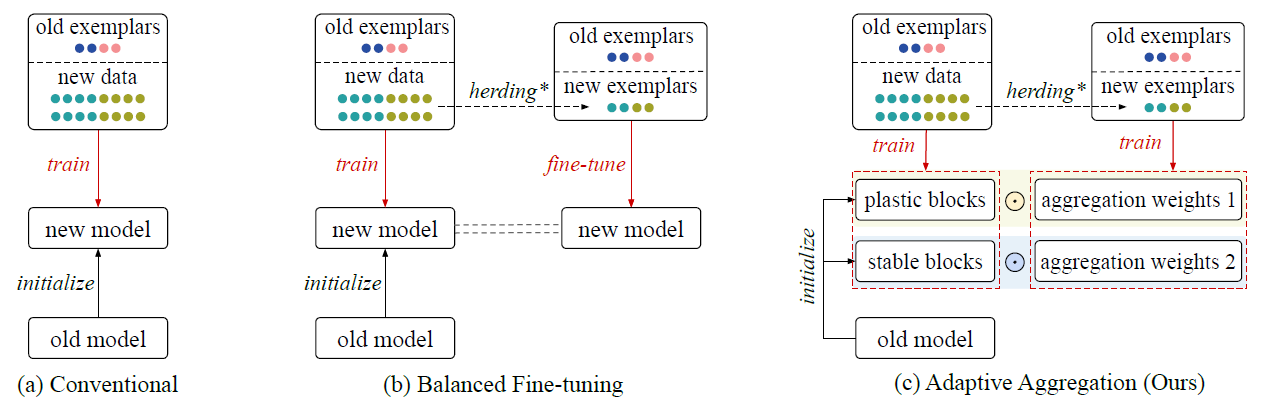
- AANets : 그림1 (c) 의 stable block (지식보존)와 plastic block(새로운 클래스 학습) . 두 블럭의 가중치 조절을 통해 블럭들의 feature map에 적용하여 합산 후에 result map을 다음 residual level로 전달한다. 이것이 dynamic하게 block usage의 균형을 잡아 aggregation weight를 갱신하는 방법이다. 전반적으로 AANet의 optimization은 이중 level로, level-1은 두 타입의 residual block에 대한 parameter학습이고, level-2는 aggregation weight 를 조정하는 것이다. 보다 구체적으로, 레벨-1은 phase에서 모든 사용가능데이터를 이용한 네트워크파라미터의 표준 최적화이고, 레벨-2는 그림.1 (c)처럼 (새로운 클래스를 downsampling)해서 만든 balanced subset을 이용한 aggregation weights를 최적화 시키는 two type blocks의 균형을 맞추는 것이 목표다. 이를 BOP(bilevel optimization program)이라 하겠다.
- 평가 : CIFAR100, ImageNet-subset, Imagenet.
- 참고 : iCaRL, LUCIR, Mnemonics Trianing, POD Net
- Cifar-100/ImageNet-subset에서 26%/15% 메모리 오버헤드가 유발되던데 오버헤드 없는 설정으로 추가실험했다. (AAnet의 old exemplars의 숫자를 줄이는 방식으로)
- Contribution :
- CIL stability-plasticity 딜레마 해결을 위한 순수한 AANets
- BOP기반 formulation과 AANet 최적화를 위한 end-to-end training solution
- 광범위한 실험.
Related Work
Incremental learning
- 목표는 일련의 훈련단계에서 incremental하게 오는 데이터를 효율적으로 학습하는 것으로, continual learning과 lifelong learning이 있다. 요즘의 incremental learning은 task기반 혹은 class기반으로 진행된다.
- task 기반 : phase마다 모든 클래스의 데이터가 제공되지만 단계마다 다른 도메인에서 가져온다.
- class 기반(CIL) : 동일한 데이터 셋을 단계마다 다른 클래스로 가져온다. (☆our work)
- related works는 주로 catastrophic forgetting해결에 중점을 두며 정규화기반,replay-기반, 매개변수 분리기반으로 나뉜다.
Regularization-based
- loss function += reularization terms 는 learning new data +=previous knowledge 와 같다.
- Li at al : knowlege distillation 정규화 제안
- Hou at al[LUCIR] : old&new class data imbalaence완화를 위한 less-forgetting 제약조건과 불균형으로 야기된 negative effect방지를 위한 inter-class separation 와 같은 새로운 정규화 용법을 도입.
- Douillard et al : spatial-based distillation loss 과 각 객체 클래스에 대한 multiple proxy vector를 포함한 representation 제안(?)
- Tao et al : topology-preserving loss를 제안하여 feature 공간에서의 topology(위상;기하)를 유지.
- Yu et al : 새로운 클래스 학습 중에 previous class의 drift(표류) 현상을 추정(estimate).
Replay-based
- old data의 tiny subset을 저장해두고 새로운 클래스를 학습할때 replay 하여 잊는걸 줄인다.
- Rebuffi et al[iCaRL] : 이 subset을 구축하기 위해 클래스당 평균 샘플과 가장 인접한 이웃을 선택.
- Liu et al[Mnemonics Training] : subset에서 샘플을 parametrerizd한 후에 전체 집합의 representation 능력을 meta-learning의 목표로 삼아 end-to-end 방식으로 자동적인 meta-optimization을 수행.
- Belouadah et al : second memorty로 old cass의 통계를 compact하게 저장하여 활용하는 것을 제안.
Parameter-isolation-based
- task-based incremental 학습에서는 쓰이지만 CIL에선 쓰이지 않는다. (비교적 힘뺐음) overwriting 파라미터로 인해 모델forgetting이 발생하는걸 막고자 다양한 incremental phased에서 다양한 모델 파라미터를 쓰려고 했다. nn의 크기가 주어지지 않는다면, old branch를 얼리는 동안 new task의 new branch가 자랄 수 있도록 했다.
- Rusu et al : 서로 다른 작업이 절실하게 요구하는 것을 네트워크에 직접 통합한 'progressive networks' 제안
- Abati et al : 각 conv 층에 task-specific gating 모듈을 붙여서 각 새로운 task를 학습하는 specific filter를 선택.
- Rajasegaran et al : 여러 task에 걸쳐 parameter을 공유하도록 유도하면서 new task에 대한 optimal paths를 점진적으로 선택
- Xu et al : 강화학습 전략을 활용해 각 task에서 가장 적합한 nn 구조를 찾는다.
- 우리는 CIL에 초점을 맞췄으며 network크기를 지속적으로 증가시키지 않는다. 메모리 예산 아래에서 우리 접근법은 related method를 초월했고 이 methods에 plug-in버전으로 적용했더니 일관적인 성능향상을 불러왔다.
Bilevel Optimization Program
더보기
- 해당 방법을 이용해 Deep model의 hyper-parameter를 최적화 한다. 기술적으로 network parameter는 한 level 에서 update되고 key hyperparameters는 another level에서 업데이트된다. 최근 incremental 학습을 해결하기 위한 몇가지 bi-level optimization-기반 접근방식이 등장했다.
- Wu at al : bilevel optimization framework를 사용하여 incremental learning model에 대한 bias correction layer를 학습했다.
- Rajasegaran et al : knowledge from all tasks를 유지하기 위한 generic model을 학습하며 new tasks를 incrementally 학습했다.
- Riemer et al : 모델이 distracting directions하는 것을 피하기 위해 previous phase와 well-aligned 하도록 갱신하여 학습했다.
우리는 bilevel optimization program 하여 AANets의 aggregation 가중치를 갱신한다.