0405 ProCa
2024.03.30 - [AI] - 0329 ProCA
이전 PLDCA에서 봤던 것을 파란색으로, 자의적인 해석은 녹색으로 칠했다. https://github.com/Hongbin98/ProCA
2. Related Work
- UDA 논문 검토 : closed-set UDA, partial DA, continual DA
- 관련 task : class incremental DA + universal DA와 실험들
2.1 UDA
- Closed-set UDA : UDA목적은 라벨많은 소스도메인을 기반으로 언라벨된 타겟도메인에서의 성능을 향상시키는 것이다. 이 영역에서 가장 보편적인 것은 closed-set UDA로써 src와 tgt에서 같은 클래스를 공유한다고 가정한다.
*high-order moments matching이란 ?
- 분포의 평균, 분산, 왜도, 첨도 중 왜도나 첨도같은 고차원 특성을 서로 유사해지도록 조정한다는 뜻이다.
-최근에는 OP-GAN을 UDA에 접목시킨 자가학습이 image content consistency를 강화를 위해 나왔다.
- Partial DA(PDA) : Closed-set UDA에 비해 PDA는 같은 label set을 제한한 대신 target label set ∈ source label set
- 일반적인 PDA의 목표 : big labeled src domain > small unlabeled target domain. 형식의 deep model transfer이다.
- inconsistent label space 를 해결하기 위해 기존에는 source sample에 class/instance-level의 transfer-ability weights를 할당했다.
- src primate classes로 야기되는 negative transfer
- BA3US : target domain을 증강하여 balanced adversarial alginment 를 수행했다.
- DPDAN : src domain 분포를 둘로 나눠 source domain의 positive part를 target domain에 align시켰다.
- 일반적인 PDA의 목표 : big labeled src domain > small unlabeled target domain. 형식의 deep model transfer이다.
- Continual DA (CDA) : 1개 이상의 unlabeled target domain 이 순서대로 다가올때, previous domain knowledge를 잊지 않고 새로운 domain을 incremental 하게 적응 시키는 것을 추구한다.
- Dlow : intermediate 상태의 continuous flow를 생성하기 위해 source와 multiple target domain 을 bridge했다.
- VDFR : domain shift와 task shift(det>seg등) 해결을 위한 variational domain-agnostic features replay
- recently GRCL : gradient of losses를 regularize하여 discriminative featrues를 학습하고 previous knowledge를 보존하고자 했다.
- 전반적으로 위 방법들은 2가지 측면 때문에 CI-UDA에 적용할 수 없다.
closed-set UDA/PDA들은 모든 target data가 사전에 이용가능하다는 가정에 의존하는데 이는 이러한 방법론들이 previou s knowledge retaining을 고려하지 않는다는 뜻이다. 반면에 CDA는 domain-shared classes detection을 무시하고 각 target domain의 label set이 source domain의 label set과 같다고 가정한다. (근데 CI-UDA는 어렵다)
2.2 Class-incremental DA
- Class-incremetal learning(CIL)과 유관한다. 모든 클래스는 점진적으로 증하가고 한 번에 증가한 새 클래스만 사용가능해진다. catastrophic forgetting 해결을 위해 기존 CIL 방법론들은 'previous classes 데이터 저장/생성하기','이전 클래스 관련 가중치 보존하기' 등으로 previous classes의 지식을 retain하려 했다.
- 최근연구는 class-incremental domain adaptation으로써 domain shift 완화와 target domain의 private class를 점진적으로 학습하는 것이 목표다. 이를 위해 부분적인 labeled target private sample을 이용한다.
- CIDA : class별 prototype을 생성하고 target-specific(대상별) latent space을 학습하여 source-free domain adaptation scenario에서 centroids를 얻었다.
- CBSC : novel class adaptation 및 domain invariant feature extraction을 위해 supervised contrastive learning을 활용했다.
- 위 Class-incremental DA 가 CI-UDA와 다른 점 두가지
Class-incremental DA CI-UDA Goals target private class를 점진적으로 학습하려함 private class 없는 target 도메인의 증분 DA이슈 처리 Target Labels one/few shot labeled target sample 필요하다. 모두 unlabeled 데이터다.
- 그래서 CI-UDA에 Class-incremental DA 방법을 적용하진 못한다.
- ProCA
- unsupervised domain alignment를 수행
- knowledge replay by identifying target label prototypes 수행
- 그래서 CI-UDA의 최초로 적용가능한 훌륭한 솔루션이 될 것이다.
3. Problem Definition
- Notation :
| Source domain | Target Domain |
| $D_s =\left\{(x_j^s,y_j^s)|y_j^s\in C_s \right\}_{j=1}^{n_s}$ | $D_t= \left\{ x_j \right\}_{j=1}^{n_t}$ |
| $n_s$ | data 쌍 $(x^s,y^s)$의 수 | $C_s$ | source label set |
| $C_t$ | target label set | $K$ | $C_s$의 클래스 수 |
- CI-UDA
- UDA 목표 : $D_s$로부터 $D_t$로 transfer knowledge
- key : domain shift완화를 위한 domain alignment
- (PLDCA에서 말하는 문제정의와 같다)
더보기기존의 UDA 방법은 일반적으로 모든 target samples가 사전에 액세스 가능하고 소스 도메인과 동일한 fixed label space(즉, Ct = Cs)를 갖는다고 가정한다. 그러나 실제 응용 프로그램에서는 대상 샘플이 종종 스트리밍 방식으로 제공되는 반면 대상 카테고리의 수는 순차적으로 증가할 수 있다. 이를 해결하기 위해 보다 실용적인 작업, 즉 labeled source samples는 항상 사용할 수 있지만 레이블이 지정되지 않은 대상 샘플은 점진적으로 제공되고 한 번에 부분적인 대상 클래스만 사용할 수 있는 CI-UDA(Class-Incremental Unsupervised Domain Adaptation)를 탐색하려고 한다. 여기서, 현재 시점에서 unlabeled target domain을 나타내기 위해 $D_t$를 재사용한다. each time step에서 target data의 label set는 source domain의 label set의 subset, 즉 Ct ⊂ Cs이다.
- 두가지 과제 :
- 어떻게 each time step 마다 두 도메인 사이에서 shared clasees 식별하지?
- 오래된 클래스의 knowledge forgetting을 완화하면서 새로운 target class는 어떻게 학습하지?
- 어렵다. 문제가 복합적이라 기존솔루션들을 적용할 수가 없다.
4. Prototype-guided Continual Adaptation
- 이전 연구에 따르면 label prototypes는 UDA나 class-incremental learning task를 독립적으로 처리하는데 효과적인 방법이다. CI-UDA에서 직접적으로 사용할 순 없지만 unified prototype-based method를 찾도록 영감을 준다. 그러나 실제로 그렇게 하기는 어렵다. src/tgt domain이 다른 라벨공간을 갖고 있기에 target label prototype을 식별하기가 어렵다. 그래서 novel Prototype-guided Continual Adaptation (ProCA) method를 제안한다.
- ProCA
- Label prototype identification : 각 time step 마다 src/tgt domain에서 shared classes detect 하면서 각 클래스의 target label prototype을 식별하고 그것을 memory bank 에 저장한다.
- Prototype-based alignment and replay : $L_{con}$을 통해 domain-invariant feature extractor 학습할 것이고 이를 위해 각 target label prototype에 대응하는 source center를 align한다.

- 저장된 label prototypes는 모델이 $L_{dis}$를 통해 이전 클래스에서 학습한 knowledge를 유지하도록 강제한다.
- 또한 $L_{ce}$는 labeled src sample과 pseudo-labeled target sample을 기반으로 한 task classification에서의 cross-entropy loss다.
- 첫번째는 each time step 마다 src domain과 tgt domain 간의 inconsistent label spaces 하에 있는 target label prototypes을 식별하는 label prototype identification stratagy를 (c.f. 섹션 4.1)을 개발했다.
- 이를 위해 먼저 domain-shared classes과 source private classes을 구별하는 shared class detection method을 제안한다.
- detected shared label set과 clustering(PLDCA와 다른 점)에 의해 생성된 target pseudo labels을 기반으로 각 shared class에 대한 target label prototypes을 식별하고 이를 기록하기 위한 adaptive memory bank P를 구성한다.
- 두번째는 언급했다시피 identified label prototypes를 기반으로 각 image prototype을 해당 source center에서 algin하고 previous classes에 대한 knowledge를 유지하도록 하는 prototype-based alignment와 replay전략(section 4.2)을 제안한다.
- 구체적으로 말하자면 feature extractor $G$를 훈련시켜 supervised contrastive loss $L_{con}$을 통해서 domain-invariant feature를 배우도록 하면 prototype-based alignment가 수행된다.
- 반면 knowledge distillation loss $L_{dis}$는 prototype-based knowledge replay에 활용한다. 또한 pseudo-labeled target data와 labeled source 데이터에 기반하여 우리는 whold model ${G,C}$를 표준 ce loss인 $L_{ce}$로 훈련할 것이다.
- 그러면 그 수식은 아래와 같다.

| ${\theta}_g $ | feature extractor G 파라미터 | ${\theta}_c $ | classificer C의 파라미터 |
| $\lambda$와 $\eta$ | trade-off parameter |
4.1 Label Prototype Identification -label prototype identification 전략
- Shared Class detection
- Pseudo Label generation for target data
- Prototype memory bank 구축
- Prototype memory bank 갱신
- Shared class detection

그림3. Art > real world, Office-Home-CI의 소스 클래스에 대한 target sample의 cumulative probabilty(CP)다. 각 time stp마다 10개의 target classes가 이용가능하다. 예를들어 step1은 class 0~9, step2는 class 10~19다. shared classes의 CP값은 source private classes보다 높은 것을 보인다. 게다가 학습중에는 step2의 16번째 CP가 step1보다 높기 때문에 우리는 그에 대응하는target class prototype을 갱신했다. - 새 unlabeled target sample이 도착하면 target sample은 unlabeled라서 src/tgt domain사이에서는 detect하기가 어렵다. 이를 해결하기 위해 pretrained source model이 shared classes와 source private classes를 predicting 하는 차이를 연구한다. 그림3을 보면 shared classes에 대한 target sample CP가 source private classes의 CP보다 더 높다. 이에 따르면 target sample의 CP를 기반으로 shared class를 detecting하는 것을 제안한다. 구체적으로는 그림4를보면 source pretrained model M을 활용해 each time step 에서 all target sample을 추론하고 각 클래스 k의 CP를 다음과 같이 구한다.
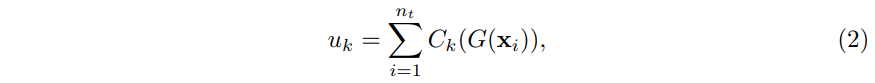
| $C_K(~)$ | softmax output prediction의 k번째 element | $n_t$ | current time의 target sample 수 |
| $u$=[$u_0$,$u_1$,$...$,$u_K$] | k classes에 대한 확률 벡터 | ||
| $\alpha$ | k가 shared class라면 $u_k$≥$\alpha$를 만족해야 class k로 결정된다. 아니라면 k는 source private class다. | ||
- generalization을 강화하기 위해 CP $u_k$는 아래와 같이 [0,1]로 normalizae했다.
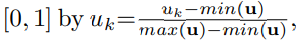
- Pseudo label generation for target data.
- 식별된 shared classes를 기준으로 target sample에 pseudo labels를 부여하는 selfsupervised pseudo-labeling 전략을 소개한다. 자세히 말하자면
| $q_i$=$G(x_i)$ | 추출된 특징 | $\widehat{y_j^k}$=$C_k(q_i)$ | class k에 대해 Classifier가 예측한 확률 |
- 처음에는 shared label 안에서 각 class k마다 initial cenroid를 구한다.
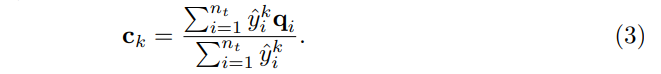
- 이러한 initialization은 서로 다른 category의 distribution을 잘 characterize할 수 있다. 이러한 centroids에 기반하여 i번째 target data의 pseudo label은 가장 가까운 centroid approach를 통해 얻게 된다.

- $\phi (., .)$는 cosine 유사도를 의미한다. psudo label $\hat{y}$∈$\mathbb{R}^1$ 은 하나의 scalar이다. pseudo label generation 동안 우리는 각 class의 centroid를 아래와 같이 업데이트 했다.

- 갱신하고 수식(4)를 기반으로 $c_k$와 가장 가까운 $q_i$의 k를 찾아냄으로써 pseudo label을 갱신한다.
- Prototype memory bank construction
- detected shared label set과 generated target psuedo labels를 기반으로 각 shared class에 대한 target label proto type을 식별한다.
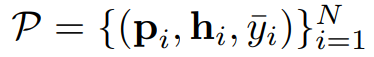
| $p_i$ | image prototype | $h_i$ | predicted soft label |
| $\hat{y}$ | predicted hard pseudo label | N | number of prototypes |
| $C_{at}$ | all seen target label set | M | 메모리뱅크에 클래스마다 저장된 이미지 프로토타입 수 |
- $N=|C_{at}|M$
- 학습동안 새로운 pseudo-labeled target class가 온다면 해당하는 target prototypes을 추가함으로써 메모리뱅크를 확장한다. 엄밀하게 말해 k번째 클래스에서 pseudo-labeled target domain을 아래와 같이 정의하는 것이다.
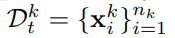
- 그리고 해당 feature center는 아래와 같이 구한다.
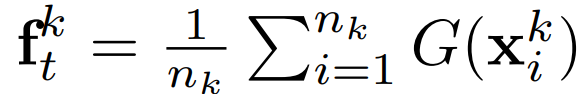
- iCaRL에 영감받아 k번째 클래스에 대한 이미지 프로토타입을 target feature center을 기반으로 centroid에 가장 근접하는 (center) feature를 가진 이미지로 선정했다.
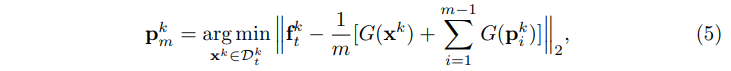
- Prototype memory bank updating
- shared class detection 중에 false shared class가 발생하면 pseudo label 생성을 발해하여 이러한 클래스들은 갱신해야 한다. 그렇게 하기 위해 cumulative probability ${\mu}_k$에 기반한 갱신 전략을 고안했다. memory bank안의 target class k 의 prototype에 대해서 ,더 높은 ${\mu}_k$가 발생하면 교체한다.
- 예를 들어 그림3에서 time step 2의 16번째 class의 누적확률이 time step 1보다 크다면, 16번째 클래스의 image prototype이 식(5)를 통해 갱신될 것이다.
Algorithm 1 Training paradigm of ProCA
- 요구사항 :
- Unlabeled target data $D_t$=$\left\{x_i \right\}_{i=1}^{n_t}$ at the current time;
- Pre-trianed source model {G,C};
- Prototype memory bank인 P;
- Training Epoch E, Training Parmeter $\mu$, $\eta, \lambda, \alpha ,T$.
- 식 (2)에 따라 shared classes Detect
$x_i$의 특징을 추출해 Classifier가 확률을 산출한다. - 식(4)에 따라 target pseudo labels를 얻는다.

특징 $q_i$와 centroid $c_k$중 가장 거리가 가까운 k를 찾는다. - for e=1 → E가 될 때까지 반복
- 식(5)에 따라 target label prototype을 갱신
클래스 k에 대한 prototype sample 의 특징을 더한것과 해당 이미지에 대한 특징을 더해 나눈 것을 target (class) feature centroid와의 거리를 구해 가장 짧은 거리의 이미지 $x^k$를 프로토타입으로 삼는다. - 특징추출기 G에 따라 target data feature을 추출한다 $G(x)$
- 분류기 C에 따라 target data prediction 을 얻는다. $C(G(x))$
- 식(7), 식(8)에 따라 $L_{con}$, $L_{dis}$ 를 연산한다.


- 식(1)을 최적화 하는 방식으로 G와 C를 갱신한다

- 식(5)에 따라 target label prototype을 갱신
- end for
- return G and C
4.2 Prototype-based Alignment and Replay
target label prototypes를 기반으로 domain shifts 및 catastrophic forgetting 문제를 처리할 새로운 prototype-based alignment 및 replay strategy을 개발했다.
- Prototype-based domain alginment
- target label prototype을 기반으로 domain shift를 확실하게 완화기위해 class-wise alignment를 수행할 수 있다.
- 이를 위해서 각 pseudo-labeled prototype과 이에 대응된 클래스의 source center을 align하는 방법을 제안한다.
- k번째 클래스에 대해서는 먼저 다음과 같이 source feature center $f_s^k$를 구한다.

같은 클래스인 source x들의 feature centroid를 구한다. - 그 다음 어떤 이미지 프로토타입 $p_i$든 anchor로써 contrastive loss를 통해 prototype alignment를 수행한다.

이 loss는 feature extractor G로 하여금 domain-invariant한 feature를 학습해 domain discrepancies를 완화시키도록 돕게한다.$v_i$=$G(p_i)$ img prototype 의 추출된 특징 $\hat{y_i}$ pseudo label $\tau$ temperature factor - Prototype-based knowledge replay
- previous classes의 target sample을 사용할 수 없기 때문에 CIUDA의 모델은 catastrophic forgetting을 얻는다. 이를 극복하기 위해 soft labels를 사용한 identified prototypes를 기반으로 knowledge distillation 방식을 채택했다. 이로써 모델로 하여금 previous classes로부터 얻은 지식을 유지하도록 강제한다.

- N은 prototype의 갯수다.
- previous classes의 target sample을 사용할 수 없기 때문에 CIUDA의 모델은 catastrophic forgetting을 얻는다. 이를 극복하기 위해 soft labels를 사용한 identified prototypes를 기반으로 knowledge distillation 방식을 채택했다. 이로써 모델로 하여금 previous classes로부터 얻은 지식을 유지하도록 강제한다.
- 여태까지 ProCa의 알고리즘1 pseudo code를 통해 요약된 것을 살펴보았고 prototype identification 의 pseudo-code 에 대한 scheme은 부록 B에 수록하였다.
<끝>
5. Experiments
5.1 Experimental Setup
- Datasets : [Office-31-CI/Office-Home-CI/ImageNet-Caltech]
- Implementation details
- pytorch로 구현한 3가지 실험으로 mean ±stdev 의 결과를 냈다.
- ImageNet으로 pretrain한 ReNet50을 backbone으로 썼고 0.0001의 SGD optimizer를 썼다.
- Compared methods
- source-only resnet50 / UDA인 DANN / partial DA인 PADA/ ETN/ BA3US/ CIDA
- Evaluation protocal : Final accuracy, Step-level accuracy, Final S-1 accuracy
5.2 Comparisions with Previous Methods


CIDA는 source private classes를 무시해 negative transfer이 발생했다는데 그렇게 생각하는 이유는 잘 모르겠다.
Domain adaptation methods는 심지어 ResNet-50보다 성능이 떨어지는데, 이는 alignment만 수행하면 현재 단계에서 모델이 대상 범주로 편향되고 이전 범주에 대한 지식을 잊어버릴 수 있음을 의미한다.

time step 1만 고려하면 CI-UDA는 standard PDA 문제가 되어버린다. 이 경우 이전 PDA 방법(즉, PDA[1], ETN[2] 및 BA3US[27])이 잘 수행되었는데 새로운 time step에서 새로운 target samples을 학습할 때는 이러한 방법은 상대적으로 유망한 성능을 유지하는 동안 심각한 성능 저하를 겪는다. time step 1와 각 time step 간에 이러한 step-1 classes의 정확도 하락을 봐라.
5.3 Application to Enhancing Partial Domain Adaptation
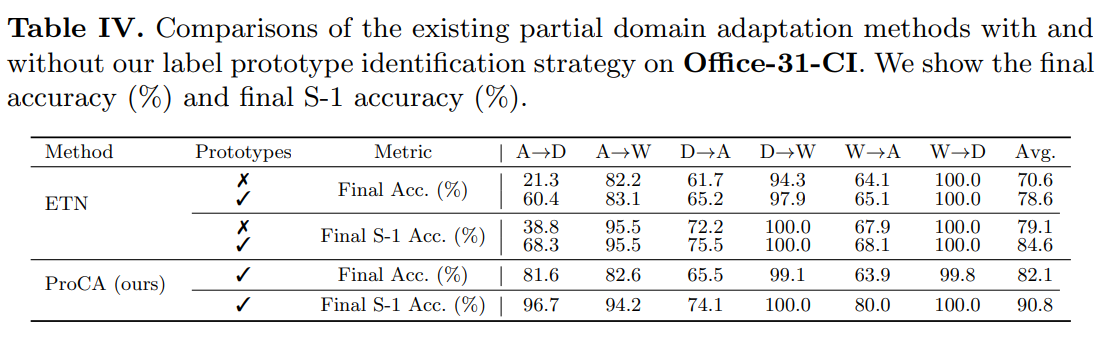


ProCA에서 손실의 유효성을 살펴보기 위해 서로 다른 손실로 최적화된 모형의 정량적 결과를 보여준다. 표 5에서 보는 바와 같이 $L_{dis}$ 또는 $L_{con}$을 도입하면 $L_{ce}$만을 사용하여 모형을 최적화하는 것에 비해 모형의 성능이 향상된다.
이와 같은 결과는 한편으로 prototype based knowledge replay가 catastrophic forgetting를 완화하여 Final S-1 Accuracy를 촉진할 수 있음을 검증하는 것이다.
5.4 Ablation studies.
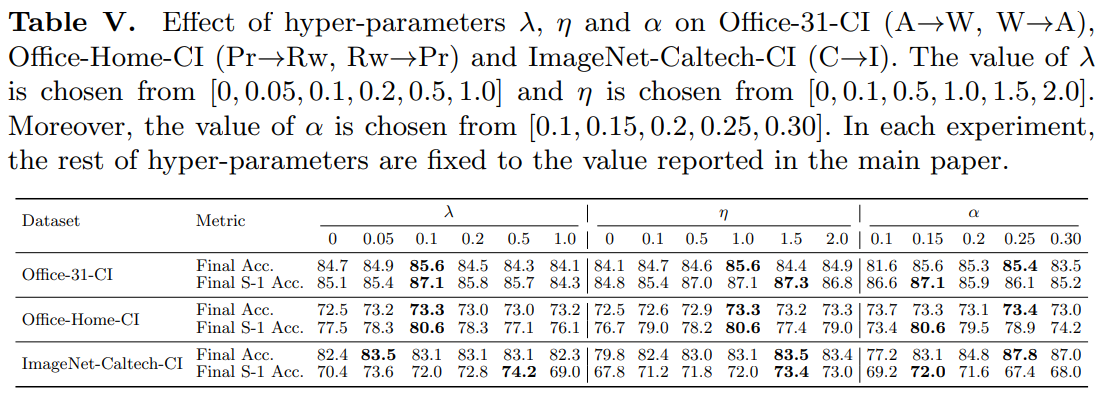
추가적으로 하이퍼 파라미터의 영향을 조사한다. 부록 F의 결과는 ProCA가 λ과 η에 민감하지 않으며, 일반적으로 λ = 0.1과 η = 1을 설정하여 ProCA의 최상의 성능을 얻을 수 있음을 보여준다.
또한 임계값이 높으면 domain-shared classes을 걸러내는 데 도움이 되므로 α = 0.15를 설정하는 것이 좋습니다. 또한 부록 F의 프로토타입 수와 증분 클래스의 영향을 조사하고 부록 G의 shared class detection 전략의 효과를 평가합니다.
6. Conclusions
- 본 논문에선 practical 전이학습과제, CI-UDA에 대해 봣다. 2가지 전략을 가진, '프로토타입으로 유도된 continual adaptation'방법을 제시했다.
- Label Prototype identification : shared class detecting의 도움으로 target label prototype을 파악하는 것이다.
- Prototype-based alignment and replay : identified label prototypes를 기반으로 prototype-guided한 contrastive alignment와 catastrophic forgetting을 각각 knowledge replay와 3가지 데이터셋을 통해 해결했다. 이 데이터셋과 ProCa에 대한 광범위한 실험을 통해 CI-UDA 처리의 domain discrepancies가 입증되었다.
+Supplementary
- 이 섹션에서는 모든 세 벤치마크 데이터셋(즉, Office-31-CI, Office-Home-CI 및 ImageNetCaltech-CI)의 각 분리된 부분집합에 포함된 클래스를 표 III과 II에 보여줍니다.
- 구체적으로, 우리는 세 벤치마크 데이터셋에서 증분 클래스의 수로 10을 선택했습니다. Office-31-CI의 경우, 클래스 이름을 알파벳 순서로 정렬하고 10개의 카테고리를 한 단계로 그룹화합니다. 결과적으로, Office-31-CI의 각 도메인은 3번의 시간 단계에 대해 3개의 분리된 부분집합을 가진다.(나머지데이터셋 지움)
- 표 III에서 보듯이, 우리는 정렬된 클래스 인덱스에 기반하여 매 10개의 카테고리를 시간 단계로 그룹화합니다. .우리는 세 데이터셋의 분할을 코드에 넣었습니다.
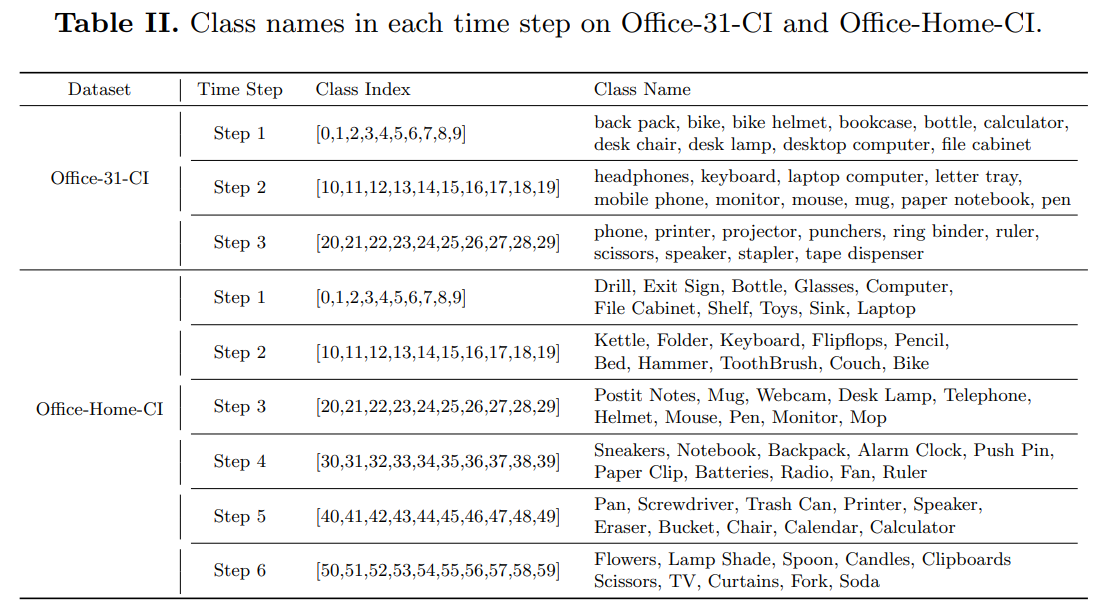
표3은 칼텍이라 뺌
- ProCA를 SGD 최적화 함수를 사용하여 학습하며, lr은 1 × $10^{-3}$, 가중치 감소는 1 × $10^{-6}$, 그리고 모멘텀은 0.9로 설정했다.
- 각 time step에서 학습을 진행할 때, pseudo label, label prototype, 그리고 source center을 각각 4, 7, 5 에포크마다 업데이트했다.. 세 데이터셋 모두 train-validation 분할이 없기 때문에, 모든 방법에 대해 마지막 에포크에서의 결과를 보고한다. 주의할 점은, 우리는 추가적인 target augmentation(예: [7] 등)을 학습이나 평가에 활용하지 않습니다.
ProCA는 높은 α로 final accuracy 측면에서 최고의 성능을 얻을 수 있지만, 임계값이 높으면 공유 클래스가 필터링될 수 있기 때문에 낮은 α(예: 0.15)를 설정하는 것이 좋다. false shared classes를 우려할 수도 있으나, 더 높은 누적 확률이 나오면 label prototype identification 방식에 의해 업데이트되기 때문에 실제로 우리 방법으로 처리가능하다.
G Effectiveness of Shared Class Detection
- 공유 클래스 탐지 전략의 효과를 추가로 조사하기 위해, 우리는 우리의 방법을 두 가지 변형과 비교한다.
- 첫 번째 변형(즉, Pseudo-labeling)은 shared class detection 전략을 제거하고 모든 클래스에 대한 대상 샘플을 직접 클러스터링한다
- 두번째 변형은(즉, Pseudo-labeling with HBW)는 클러스터링 방법[26]에 HBW 전략[16]을 적용하고 타겟 샘플에 대한 의사 pseudo-labels을 생성한다. 표 VII에 나타낸 바와 같이, [26]의 label space inconsistency의 최종 정확도는 열등한 정확도(74.1% Avg. Acc.)를 산출하고 심지어 Office-31-CI에서 소스 전용(77.5% Avg. Acc., ResNet-50)보다 성능이 떨어진다. 도메인 간의 라벨 공간 불일치에 직면할 때 pseudo labels generated by clustering에 노이즈가 있을 수 있기 때문이다. 이래서인지 두 번째 변이체도 성능 저하를 겪는다(66.6% Avg. Acc.). 그 이유는 HBW 전략이 CI-UDA에서 source-positive and source-negative distributions의 최상의 distribution을 얻지 못한 이유로 보인다(부록 A 참조),
- 따라서 the source positive classes and the shared classes를 잘 구별할 수 없다(cf. 표 I). 대조적으로, 공유 클래스 탐지 전략을 사용할 때 ProCA는 다양한 학습 단계(cf. 표 I)에서 공유 클래스를 잘 탐지하여 훨씬 더 나은 성능을 달성한다(cf. 표 VII). 이러한 결과는 CI-UDA에서 기존 기준선에 비해 공유 클래스 탐지 전략의 우수성을 보여준다.

